

محبوبترینها
آیا میشود فیستول را عمل نکرد و به خودی خود خوب میشود؟
مزایای آستر مدول الیاف سرامیکی یا زد بلوک
سررسید تبلیغاتی 1404 چگونه میتواند برندینگ کسبوکارتان را تقویت کند؟
چگونه با ثبت آگهی رایگان در سایت های نیازمندیها، کسب و کارتان را به دیگران معرفی کنید؟
بهترین لوله برای لوله کشی آب ساختمان
دانلود آهنگ های برتر ایرانی و خارجی 2024
ماندگاری بیشتر محصولات باغ شما با این روش ساده!
بارشهای سیلآسا در راه است! آیا خانه شما آماده است؟
بارشهای سیلآسا در راه است! آیا خانه شما آماده است؟
قیمت انواع دستگاه تصفیه آب خانگی در ایران
نمایش جنگ دینامیت شو در تهران [از بیوگرافی میلاد صالح پور تا خرید بلیط]
صفحه اول
آرشیو مطالب
ورود/عضویت
هواشناسی
قیمت طلا سکه و ارز
قیمت خودرو
مطالب در سایت شما
تبادل لینک
ارتباط با ما
مطالب سایت سرگرمی سبک زندگی سینما و تلویزیون فرهنگ و هنر پزشکی و سلامت اجتماع و خانواده تصویری دین و اندیشه ورزش اقتصادی سیاسی حوادث علم و فناوری سایتهای دانلود گوناگون
مطالب سایت سرگرمی سبک زندگی سینما و تلویزیون فرهنگ و هنر پزشکی و سلامت اجتماع و خانواده تصویری دین و اندیشه ورزش اقتصادی سیاسی حوادث علم و فناوری سایتهای دانلود گوناگون
آمار وبسایت
تعداد کل بازدیدها :
1854735022













متن کاوي
واضح آرشیو وب فارسی:راسخون:
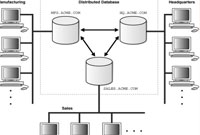
متن کاوي متن کاوي کاربرد داده کاوي براي فايل هاي ساخت نيافته يا با ساخت يافتگي کم است. داده کاوي از مزيت زيرساخت داده ذخيره شده براي اقتباس اطلاعات مفيد اضافي بهره مي برد. مثلاً، با به کار بردن داده کاوي بر پايگاه داده مشتري، يک تحليل گر ممکن است پي ببرد که هر کس که محصول A را مي خرد، هم چنين محصولات B وC را در شش ماه آينده مي خرد. متن کاوي با اطلاعات کمتر ساخت يافته کار مي کند. اسناد به ندرت داراي يک زير ساخت داخلي قوي هستند و هنگامي که آن ها چنين هستند، اغلب به فرمت سند تمرکز دارند تا محتواي سند. متن کاوي به سازمان ها کمک مي کند: *محتواي"پنهان" اسناد را بيابند، از جمله روابط مفيد اضافي. *اسناد را بين بخش هاي توجه نشده قبلي مرتبط کنند (مثلاً، پي ببرند که مشتريان در دو بخش متفاوت محصول، داراي مشخصه هاي يکسان هستند). *اسناد را با مضامين رايج گروه بندي کنند (مثلاً، تمام مشتريان يک شرکت بيمه که داراي شاکيان يکسان هستند و خط مشي هاي خود را لغو مي کنند). متن کاوي چيزي شبيه موتور جستجو در وب نيست .در يک جستجو، تلاش مي کنيم آن چه را که ديگران آماده کرده اند، بيابيم. با متن کاوي، مي خواهيم الگوهاي جديد را کشف کنيم، قطعات دانشي که ممکن است آشکار يا شناخته شده نباشند. لزوماً در بردارنده جزييات ايندکس هاي عددي با معني از متن ساخت نيافته و سپس پردازش آن ايندکس ها، و استفاده از الگوريتم هاي داده کاوي مختلف است. با ايجاد اين ايندکس هاي عددي، مي توانيم اسناد را برحسب مفاهيم کليدي خلاصه کنيم، اسناد را بر طبق شباهت خوشه بندي کنيم، روابط بين اسناد را بصري کنيم و الي آخر. در واقع، سازمان ها در حال حاضر تشخيص داده اند که يک منبع عمده مزيت رقابتي دانش ساخت نيافته موجود در حافظه دانش سازمان به شکل اسناد، يادداشت ها، ايميل ها، سياست ها و رويه ها، صورت جلسات و غيره است. تمام اين اطلاعات متني بايد کدگذاري و اقتباس شوند، بنابراين ابزارهاي داده کاوي پيش بينانه مي توانند به سازمان کمک کنند ارزش واقعي را از اين مخزن توليد کند. برخي سازمان ها از متن کاوي به عنوان يک واژه کلي براي نشان دادن تمام انواع پردازش هاي متني استفاده مي کنند. ولي حداقل سه ويژگي در اين حوزه پديدار شده اند: بازيابي اطلاعات، اقتباس اطلاعات و خلاصه سازي اطلاعات. ابتدا، بازيابي اطلاعات در زمينه متن کاوي به پرس و جوي متن،يافتن متن و پردازش اطلاعات متني برمي گردد. به علاوه، از پردازش زبان طبيعي يا زبان شناختي کامپيوتري براي تحليل و پردازش استفاده مي شود. اين مورد معمولاً، اقتباس اطلاعات گفته مي شود. مثلاً، برنامه هايي براي خواندن خودکار هزاران رزومه و اقتباس اطلاعات کليدي از قبيل نام ها، آدرس ها و مهارت ها نوشته شده است. هم چنين برنامه هايي وجود دارد که خلاصه اسناد را به طور خودکار فراهم مي کند. يک توضيح خيلي خوب از اين قابليت را مي توانيد در newsinessence.com ببينيد. بر طبق اين وب سايت، سيستم newsinessence اسناد را از تعدادي سايت خبري جمع آوري کرده، سيستم هايي از قبيل newsinessence، مثال هاي خوبي از اقتباس اطلاعات هستند و نگاهي اجمالي بر توان پردازش طبيعي دارند. *تحليل کيفي اسناد براي تشخيص تقلب. اين اسناد به ايندکس هاي عددي تجزيه شده و سپس تکنيک هاي مختلف داده کاوي از فبيل شبکه هاي عصبي براي يادگيري و تشخيص اکاذيب در اسناد استفاده مي شوند. شايد يکي از بزرگ ترين کاربردهاي متن کاوي به طور کلي و اقتباس اطلاعات به طور خاص، علوم زيست شناسي باشد. داده جمع آوري شده و کامپايل شده شامل اطلاعات متني مي باشد. اين امر منجر به فعاليت زيادي در زمينه اعمال تکنيک هاي متن کاوي بر حوزه زيست شناسي مي شود. امنيت کشور، از ناحيه ديگري است که اين نوع رشته در کاربردها در آن به چشم مي آيد در بخش بعد، برخي مثال ها را بحث مي کنيم که در آن ها، متن کاوي و وب کاوي با هم ترکيب شده اند. پرواز از طريق متن: ثابت شده متن کاوي ابزار ارزشمندي در اقتباس دانش سازماني از گزارشات به شکل ديجيتال است. تحليلگران از نرم افزار متن کاوي براي تمرکز بر نواحي کليدي از طريق شناسايي الگو استفاده مي کنند. مثلاً، شرکت ها در صنعت هواپيمايي مي توانند متن کاوي را بر گزارشات تصادفي براي افزايش کيفيت دانش سازماني به کار برند. آن ها مي توانند مشکلات مکانيکي، سازماني و رفتاري را به روشي منظم از طريق کاربرد متن کاوي مطالعه کنند. خطوط هوايي با تحليل کامل و نظامند از عمليات کار مي کنند. يک گزارش سانحه هنگامي تهيه مي شود که رويدادي روي مي دهد که ممکن است منجر به مشکلي گردد. مسائل کليدي ممکن است از تعداد زيادي از گزارشات سانحه با استفاده از متن کاوي شناسايي شوند. پايگاه هاي داده عظيمي که خطوط هوايي نگهداري مي کنند داراي تفسير انساني محدودي هستند و اصطلاح شناسي که براي يک کامپيوتر داريم، متفاوت از انسان است. مثلاً، داده هايي از Aer Lingus (aerlingus.com در طي دوره زماني ژانويه 1998 تا دسامبر 2003 که براي يافتن الگوهاي و وابستگي ها استفاده شد، منجر به تحليل بيشتر و توسعه مدل گرديد. Aer Lingus از نرم افزار داده کاوي و متن کاوي PolyAnalyst (megaputer.com استفاده مي کند. هدف آن، بصري کردن فرآيندي است که بررسي کنندگان مي توانند به طور منظم براي شناسايي الگوها و وابستگي ها در انواع حوادث، مکان ها، زمان ها و ساير جزييات حادثه از آن استفاده کنند. در ابتدا واژه هايي که بيشترين تکرار رخداد را داشته باشند، شناسايي مي شدند. PolyAnalyst همراه با واژه نامه اي است که کامل نيست ولي نقطه شروع ارزشمندي براي تحليل متن است. PolyAnalyst ومي تواند فهرستي از واژه هاي کليدي (يا معادل معناي آن ها) را که داده ها رخ داده است، توليد کند. گزارشي تحت عنوان گزارش واژه هاي تکراري ايجاد مي شود که حاوي واژه هاي شناسايي شده به همراه فرکانس آن هاست. هدف، شناسايي خوشه هاي جالب است. يک خلاصه داستاني، مجموعه اي از واژگان را به همراه دارد که توضيحات داستاني را به گروه هايي با معني تقسيم مي کند .مثلاً، واژه کليدي ريختن (spillage) مي تواند مربوط به چهار واژه کليدي ديگر باشد: غذا(food)، سوخت(fule)، شيميايي(chemical) و سرويس بهداشتي (toilet). از اين واژه هاي کليدي، برحسب spillage،food از لحاظ معنايي مرتبط با caffee، tea و drinkاست. بنابراين، food گره طبقه مي شود و محصولات غذايي مختلف که تحت عنوان spilled گزارش مي شوند، با food تطابق دارند. متن کاوي گزارشات سواغ هوايي مي تواند سوانحي را شناسايي کند که ممکن است منجر به دردسر شده باشند. متن کاوي مي تواند با مجموعه بزرگي از گزارشات داده سانحه براي تأييد اعتبار تئوري هاي از پيش تعيين شده و براي برگزيدن الگوهاي جديد دانش استفاده شود. چگونه متن کاوي را انجام دهيم: فرآيند متن کاوي را توصيف کردند. آن هم چنين بيان کردند چگونه fireman fund insurance company از متن کاوي براي کمک به پيش بيني ادعاهاي مورد انتظار استفاده کرد و فهميد چرا نتايج از پيش بيني ها منحرف شد. متن کاوي براي اقتباس موجوديت ها و اشيا براي تحليل فرکانس، تعيين فايل هايي که صفات خاصي براي تحليل آماري بيشتري دارند و ايجاد ويژگي هاي داده کاملاً جديد براي مدلسازي پيش بيني استفاده شد. اولين اين سه روش، در ارتباط با نمونه هايي از جمله لاستيک هاي firestone در ford suvs استفاده شد. اقتباس واژه، اساسي ترين شکل متن کاوي است. شبيه تمام تکنيک هاي متن کاوي ديگر، اطلاعات را از داده ساخت نيافته به يک فرمت ساخته يافته نگاشت مي کند. ساده ترين ساختمان داده در متن کاوي، بردار ويژگي يا ليست وزن دار کلمات است. مهم ترين کلمات در يک متن به همراه اندازه اهميت نسبي آن ها فهرست مي شود. متن به فهرستي از واژگان و وزن ها کاهش مي يابد. کل معنا شناختي1 متن ممکن است وجود نداشته باشد، ولي مفاهيم کليدي شناسايي مي شوند. براي انجام اين کار، متن کاوي شامل اين مراحل است: 1-حذف کلماتي که معمولاً استفاده مي شوند (مثل the،and وother). اين ها معمولاً کلمات توقف ناميده مي شوند. 2-جايگزيني کلمات با واژه ها يا ريشه هايشان (مثلاً، حذف شکل جمع کلمات و حروف ربط مختلف و صرف ها). در اين مرحله، واژه هايphoning phones،phoned،به phone نگاشت مي شوند. اين ها الگوريتم هاي ريشه يابي2 گفته مي شوند. 3-مترادف ها و عبارات را در نظر بگيريد. کلماتي که مترادف هستند بايد به طريقي ترکيب شوند. مثلاً، student و pupil بايد با يکديگر گروه بندي شوند. هم چنين بايد عبارات را درنظر داشت. همان گونه که توسط statsoft اشاره شد، Microsoft Windows به سيستم عامل کامپيوتر اشاره دارد، ولي به طور مجزا، Windowsممکن است به يک پروژه خانه سازي مرتبط تر باشد. 4-وزن هاي ريشه هاي باقيمانده را محاسبه کنيد. رايج ترين روش، محاسبه فرکانسي است که کلمه با آن پديدار مي شود. دو معيار رايج وجود دارد: واژه فرکانس يا tf factor ، تعداد واقعي دفعاتي را که يک کلمه در يک سند ظاهر شده است، اندازه گيري مي کند و فرکانس سند وارون يا idf factor تعداد دفعاتي را نشان مي دهد که کلمه در تمام اسناد در يک مجموعه آمده است. استدلال اين است که يک tf factor بزرگ، وزن را افزايش مي دهد، در حالي که يکidf factor بزرگ، آن را کاهش مي دهد، زيرا واژه هايي که مکرراً در تمام اسناد روي مي دهند، کلمات رايجي در صنعت هستند و مهم در نظر گرفته نمي شوند. مثلاً فرض کنيد که تحليل يک پاراگراف منجر به مشاهده اي مي شود که حدود 20 واژه با 28 رخداد وجود دارد هنگامي که کلمات رايج را factor out کنيم. در اين جا، ليستي از واژه هايي را داريم که بيش از يک بار ظاهر شده اند، به علاوه فرکانس هاي نسبي آن ها (tf factorها) از مجموع 28 رخداد (جدول ذيل). هنگامي که تمام کلمات مهم در پاراگراف را در نظر مي گيريم، آن ها نيمي از اهميت کلي خود را تشکيل مي دهند و مي توانند براي تعيين معنا شناختي خود استفاده شوند. بديهي است، اين پاراگراف درباره متن کاوي است (0/1429=وزن) و شامل متن و داده با ساختار و وزن است. اجزاي متعددي در يک سيستم متن کاوي وجود دارند، از جمله اين موارد: *سيستمي براي مديريت اسناد به شکل هاي گوناگون (مثلاً، متن ساده، فرمت هاي واژه پرداز وPDF) از منابع مختلف (مثلاً، فايل ها، فرم ها وب، ايميل ها). *اجزاي مورد استفاده براي پردازش اين اسناد و ايجاد فايل هاي داده اي که مي توانند متن کاوي شوند. اين ها عبارتند از: تقسيم کننده هاي جملات، بخش هايي از کلام، taggerها، ...، پارسرهاي کامل، ...، خلاصه کننده ها و الي آخر. *ابزارهاي داده کاوي از قبيل الگوريتم هاي خوشه بندي، الگوريتم هاي طبقه بندي و الي آخر. کلاً دو چارچوب کاري منبع باز براي دو وظيفه اول وجود دارد. يک چارچوب کاري عمومي که GATE3 ناميده مي شود که از وب سايت دانشگاه شفليد در آدرس gate.ac.uk در دسترس است. پلت فرم ديگر که تحت حمايت JBM است، UIMA4 ناميده مي شود که در آدرس research.ibm.com/UIMA در دسترس است. علاوه بر اين ابزارها، تعدادي از فروشندگان داده کاوي، قابليت هاي متن کاوي را در بسته هاي نرم افزاري خود ارايه مي دهند. به دليل اين که ناحيه هنوز در دست تحقيق و توسعه است، قابليت هاي نرم افزار به سرعت تغيير مي کند. ليستي از ابزارها و فروشندگان محبوب داده کاوي بدين صورت است: *ASA Text Miner asa.com *IBM Intelligent Miner for Text IBM.COM *SPSSLexiquest spss.com *Insightful Mnier for Text INSIGHTFUL.COM *Megaputer Intelligence Text Analyst megaputer.com مثال خاصي مربوط به تحليل مرورهاي اتومبيل، توسط اشخاص مختلفي مهيا شده است. اين نوع "ديدگاه کاوي"، کاربرد رايج ديگري از متن کاوي است. با توجه به اين که شايد 80درصد تمام داده هاي غير عددي که ما جمع آوري و ذخيره مي کنيم، به فرمت متن مي باشند، طبيعي است که متن کاوي به عنوان يک ناحيه در حال رشد رواج يافته است. هر چند ما قابليت هاي پردازش زبان طبيعي را هنوز به طور کامل نداريم، بيشتر پيشرفت ها در اين حوزه در سال هاي گذشته صورت گرفته است. اين ناحيه اي است که پتانسيل قابل توجهي براي نسل بعدي کاربردهاي مفيد در آن وجود دارد. منابع: J.Froelich,S.Ananyan, and D.L Olson, "Business Inteligence Through Text Mini."Business Intelligence Journal, Vol.10,No. 1,Winter 2005.p.43-50;and Gain Full Value from Text Respones, spss.com/textanalysis_surveys/ (accessed April 2006) ماهنامه ي رايانه شماره 188
این صفحه را در گوگل محبوب کنید
[ارسال شده از: راسخون]
[مشاهده در: www.rasekhoon.net]
[تعداد بازديد از اين مطلب: 476]

-
گوناگون
پربازدیدترینها