

پرچم تشریفات با کیفیت بالا و قیمت ارزان
پرواز از نگاه دکتر ماکان آریا پارسا
دکتر علی پرند فوق تخصص جراحی پلاستیک
تجهیزات و دستگاه های کلینیک زیبایی
سررسید تبلیغاتی 1404 چگونه میتواند برندینگ کسبوکارتان را تقویت کند؟
چگونه با ثبت آگهی رایگان در سایت های نیازمندیها، کسب و کارتان را به دیگران معرفی کنید؟
بهترین لوله برای لوله کشی آب ساختمان
دانلود آهنگ های برتر ایرانی و خارجی 2024
ماندگاری بیشتر محصولات باغ شما با این روش ساده!
بارشهای سیلآسا در راه است! آیا خانه شما آماده است؟
بارشهای سیلآسا در راه است! آیا خانه شما آماده است؟
قیمت انواع دستگاه تصفیه آب خانگی در ایران
نمایش جنگ دینامیت شو در تهران [از بیوگرافی میلاد صالح پور تا خرید بلیط]
9 روش جرم گیری ماشین لباسشویی سامسونگ برای از بین بردن بوی بد
ساندویچ پانل: بهترین گزینه برای ساخت و ساز سریع
مطالب سایت سرگرمی سبک زندگی سینما و تلویزیون فرهنگ و هنر پزشکی و سلامت اجتماع و خانواده تصویری دین و اندیشه ورزش اقتصادی سیاسی حوادث علم و فناوری سایتهای دانلود گوناگون
تعداد کل بازدیدها :
1848645080













آماده سازي داده ها براي داده کاوي
واضح آرشیو وب فارسی:راسخون:
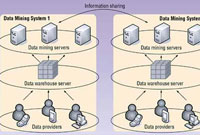
آماده سازي داده ها براي داده کاوي مقدمه : امروزه ديگر مشکل کمبود داده و اطلاعات روبرو نيستيم و به جاي آن با مسأله داده ها و اطلاعات درست ، از ميان حجمي انبوه از داشته ها روبروييم. از آن جا که درک روابط و ساختار حاکم بر داده ها واطلاعات، مي تواند دانشي گرانبها ارايه نمايد؛ نيازمند استفاده از مکانيسمي هستيم تا به بهترين وجهي عصاره اين انبوه داشته ها تهيه شده و به کار گرفته شود. از اين رو استفاده گسترده از تکنيک ها ومکانيسم هاي داده کاوي 1، متن کاوي 2، وب کاوي 3 و دانش کاوي 4؛ بيش از پيش در کانون توجه قرار گرفته است. از آنجا که؛ دستيابي به نتايج واقعي و مؤثر از اين مکانيسم ها؛ بدون برخورداري از ورودي هاي صحيح ، قابل اعتماد و مؤثر، ممکن نيست؛ پيش از هر تحليلي بايستي از صحت و تناسب داده ها و اطلاعات موجود اطمينان داشته باشيم. اين موضوع حياتي سبب شده تا ، آماده سازي داده و اطلاعات پيش از به کارگيري واقعي آن ها سنگ بناي تحليل قابل اعتنايي باشد. با توجه به گستردگي اين بحث ،در ادامه تنها بخشي از بحث آماده سازي داده ها ارايه شده و تشريح ساير موارد و ابزارهاي موجود براي اين کار به بعد موکول شده است. آماده سازي داده ها 5 براي داده کار : از داده کاوي؛ به عنوان مرحله اي از فرايند کشف دانش که الگوها و يا مدل ها را در ميان انبوهي از داده ها پيدا مي کند؛ ياد مي شود. خروجي فرايند داده کاوي معمولاً غير بديهي و البته درک است. علاوه بر اين، داده کاوي علمي است که از تلفيق علوم متفاوت همچون؛ آمار، يادگيري ماشيني، پايگاه هاي اطلاعاتي و مانند آن شکل مي گيرد و ماده اوليه به کار رفته در آن، داده (اطلاعات) است. از اين رو سنگ بناي عمليات داده کاوي خوب، به کارگيري و دسترسي به داده هاي اوليه خوب ومناسب است؛ که از آن به آماده سازي يا پيش پردازش 6 داده ها ياد مي شود. در واقع براي کشف دانش به کمک داده کاوي بايستي مقدماتي صورت گيرد؛ که مجموعه اين اقدامات را آماده سازي داده ها گويند(شکل1).
.JPG)
اهميت آماده سازي داده ها : اهميت آماده سازي داده ها به دليل اين واقعيت است که؛ "فقدان داده با کيفيت برابر با فقدان کيفيت در نتايج کاوش است" 7 و " ورودي بد خروجي بد به دنبال دارد"8 در جدول 1 مقايسه اي بين اهميت آماده سازي داده ها نسبت به ساير گام هاي کشف دانش به کمک داده کاوي صورت گرفته است. با اين حال، متأسفانه بسياري اهميت آماده سازي داده ها را فراموش کرده و يا آن را کم اهميت مي انگارند. از اين رو تلاش هاي بسياري براي بسط و توسعه آماده سازي داده ها در داده کاوي روي داده است.وظيفه اصلي پيش پردازش داده ها؛ سازمان دهي داده ها در شکل هاي استاندارد براي داده کاوي و يا ساير عمليات مبتني بر کامپيوتر است؛ که در ادامه مو
.JPG)
رد اشاره قرار گرفته است. کارهاي عمده در آماده سازي يا پيش پردازش داده ها : 1-فهم داده:با کمک اين موضوع، مي توان مراحل بعدي عمليات داده کاوي را بهبود داد. به اين معني که مي توان جامع و مانع بودن داده ها، هدف و کاربرد داده ها و مواردي از اين دست را درک کرد تا ضمن افزايش قابليت اطمينان به عمليات داده کاوي، سرعت انجام کار نيز افزايش يابد. 2-پاک سازي داده: اين مرحله شامل؛ پر کردن داده هاي گم شده، هموار کردن نويزها، شناخت و حذف داده هاي پرت و بر طرف کردن ناسازگاري هاست. 3- يکپارچه سازي داده: اين موضوع، معمولاً به هنگام تلفيق چندين پايگاه داده يا فايل اهميت مي يابد. مسايلي هم چون افزونگي داده ها در اين دسته قرار مي گيرند. 4-تبديل داده: در اين مرحله از پيش پردازش داده ها، با عملياتي همچون نرمال سازي، تغيير و تجميع داده ها روبرو هستيم. 5-کاهش داده و کاهش بعد: هدف از اين مرحله آن است که به حجم کوچک تري از داده ها دست يابيم. نکته مهم در اين مرحله از آماده سازي داده ها، آن است که دست يابي به نتايج تحليلي مشابه با اصل و تمام داده ها تضمين گردد؛ چرا که در غير اين صورت اين کاهش اثر مثبتي براي ما در پي نخواهد داشت. از آن جا که، هر يک از موضوعات مطرح شده در پيش پردازش داده ها، نيازمند بحثي مفصل و طولاني در مفاهيم ودر تکنيک هاي اجرايي است؛ ارايه آن ها در اين مجموعه نمي گنجد. از اين رو، با توجه به اهميت موضوع پاک سازي داده ها و عموميت آن در هر نوع عمليات آماده سازي براي داده آمايي، در ادامه، بيشتر اين مبحث را مورد توجه قرار داده و ساير موارد را به مقالات ديگري موکول خواهيم کرد. پاک سازي داده ها: در پاک سازي داده ها به نوعي با تميز کاري داده که گاهي تنظيف داده نيز ناميده مي شود؛ روبروييم. پاک سازي داده ها، فرآيند تشخيص و حذف يا تصحيح اطلاعات در يک پايگاه داده است که داراي برخي خطاهاست. اهميت اين فرايند تا آن جاست که، قيمت نرم افزارهاي مربوط به تميز کردن داده ها بسيار گزاف و خارج از تصور بسياري افراد است. محدوده قيمت نرم افزارهاي خوب مربوط به تميز کردن داده ها بين 000,20 تا 000,300 دلار قيمت است. وظايف پاک سازي داده: الف)اکتساب داده و فراداده: در اين مرحله، مواردي همچون شناخت نقش، نوع و جزييات کاربردي داده مورد بررسي قرار مي گيرد. به علاوه در مواردي که نياز است تا انباره هاي داده و بازارهاي داده اي ساخته شوند ممکن است نيازمند ساخت فراداده براي داده هايمان باشيم. ب)پر کردن داده هاي گم شده/مفقوده: گاهي با مشکل فقدان داده ها روبرو هستيم. دلايل مختلفي براي نبود داده ها ذکر شده است؛ که عبارتند از: *داده ها هنگام ورود حايز اهميت نبوده اند. *در تجهيزات ثبت داده ها ايراد وجود دارد. *به خاطر دشواري فهم، داده وارد نشده است. *داده مورد نظر، با داده ديگر ناسازگار بوده و به ناچار حذف شده است. حال بايد ديد که چگونه بايد با اين مشکل برخورد کرد. انتخاب روش برخورد با داده ها که وجود ندارد؛ بستگي به شرايط مسأله دارد. يکي از شرايط موثر در اين تصميم گيري ها آن است که دريابيم چه عاملي دليل فقدان داده ها بوده است. برخي داده ها مفقوده کاملاً از نظر آماري غير وابسته به داده هايي است که تا کنون مشاهده شده ان ؛ اين داده ها را مفقود شده ي کاملاً تصادفي 9 مي گويند. در برخي موارد نيز مقادير مفقوده، تصادفي 10 هستند و به تعدادي از متغيرها يا طبقه داده هاي پيش بيني کننده مشروط مي باشند. دسته اي ديگر از داده هاي مفقوده نيز، غير قابل چشم پوشي 11 هستند؛ به اين معنا که اين نوع داده هاي مفقوده به کمک داده هاي مشاهده شده قبل از خود قابل نقل هستند. اين قبيل تفاوت ها سبب مي شود که روش هاي متفاوتي براي برخورد با مقادير مفقوده مورد استفاده قرار گيرد. حذف رکورد: اين روش براي عمليات دسته بندي و بر روي داده هاي طبقه اي صورت مي گيرد. نکته اي که بايد مد نظر باشد آن است که اگر تعداد داده هاي مفقوده زياد باشد؛ استفاده از اين روش سبب مي شود که حجم نمونه به شدت کاهش يابد. اين مشکل به شکل ويژه هنگامي اثرات خود را بر نتايج نشان مي دهد که برخي از نمونه داده ها بسيار نادر و کم بوده و حذف رکورد مربوط به آن ها، سبب از دست دادن نمونه اي با ارزش شود. از اين رو حذف رکورد بايستي در موارد خاص انجام گيرد. حذف مشاهده: اين انتخاب زماني روي مي دهد که رکورد داراي مقدار مفقوده، مورد نياز باشد؛ چرا که در غير اين صورت بود يا نبود مقدار براي ما مهم نيست. البته در صورت نياز به استفاده از اين روش بايد به ياد داشته باشيم که محاسبات انجام شده براي مقادير آمار توصيفي؛ از قبيل ميانگين، واريانس و کواريانس به اندازه هاي متفاوت نمونه مربوط خواهد شد که تأثير آن بايد مد نظر باشد. پر کردن به صورت دستي: همان گونه که قابل پيش بيني هم مي باشد اين روش چندان عملي نيست؛ چرا که پيدا کردن و اصطلاحات لازم زمان بر است. البته در برخي مواقع اي تنها راه حل ممکن است. مثلاً، دو نام و آدرس فرضي محمد رحيمي ساکن تهران و محمدامين رحيمي ساکن تهران را در نظر بگيريد. اگر اين دو نفر دقيقاً يکي بوده و تمامي ساير مشخصات آن ها نيز يکي باشند؛ تشخيص و رفع اين مشکل ممکن است به کمک کامپيوتر مقدور نباشد. البته اين موارد بسيار محدود است. پر کردن به صورت خودکار: اين راه حل داراي چندين زير روش است پر کردن خودکار به چند روش زير ممکن است: پرکردن با مقدار ثابت سراسري: در اين موارد مقادير مفقوده با مقداري هم چون، Unknown پر مي شوند. مسأله اي که در اين صورت با آن مواجه خواهيم بود آن است که، ممکن است در حجم بالاي داده ها ويژگي مقدار دهي شده با اين مورد، جزء داده هاي محاسباتي محسوب شده ودر محاسبات منظور گردد؛ و به اين شکل ايجاد خطا نمايد. به علاوه هنگامي که عمليات پاگ سازي داده ها براي ساخت انبار داده استفاده مي شود، اين روش انتخاب مناسبي نخواهد بود. پرکردن با ميانگين ويژگي: استفاده از اين روش ممکن است سبب شود تا به دليل تاثير مقادير نسبت داده شده به اين ويژگي، نتايج به دست آمده به نفع اين ميانگين باياس شود؛ حتي ممکن است اتخاذ اين روش سبب حذف يا انتقال رکوردهاي مربوط به يک دسته خاص از داده ها به سمت دسته نتايج ديگري شده و يک دسته مهم و واقعي از نتايج را ناديده بگيريم. پرکردن با مقادير با احتمال بيشتر: اين روش که پرکاربردترين روش قابل اعتماد است، شامل روش هاي استنتاجي و به کارگيري فرمول هاي بيزين، رگرسيون و درخت تصميم است. به نوعي در اين روش ها بر اساس استنتاج منطقي که مبتني بر نوع اطلاعات موجود است؛ عمل پيش بيني صورت مي گيرد. علاوه بر اين موارد؛ روش هاي ديگري هم چون، پر کردن مقادير با ميانگين ويژگي براي کلاس هاي مشابه، نيز وجود دارد که چندان متداول نمي باشند. باز هم بايستي يادآوري کنيم که ، نوع داده ها و شناخت آن ها قبل از پرکردن مقادير مفقوده ضروري است. مثلاً نمي توان داده طبقه اي را با روش ميانگين ويژگي پرکرد، چرا که ميانگين براي اين نوع داده ها قطعاً بي معنا خواهد بود. درک اين موارد در مواجهه با اين قبيل مشکلات اهميتي حياتي دارد. ج)حل مشکل افزونگي(در عمليات تجميع داده ها): همان گونه که مي دانيد؛ براي کار با داده ها در بسياري مواقع، آن ها را از منابع و پايگاه داده هاي مختلف در کنار يکديگر تجميع مي کنيم. در داده کاوي اين موضوعات در قالب ساخت بازارهاي داده و انبارهاي داده مورد بررسي قرار مي گيرد که نيازمند بحثي مفصل است. به هر حال پايگاه هاي مختلف داده هنگامي که گسسته از يکديگر طراحي مي شوند؛ به ناچار داراي فيلدهاي و داده ها ي يکساني هستند که اتفاقاً داده هاي حياتي پايگاه داده ها و سيستم هاست. براي اين گونه مسايل روش هاي متعددي وجود دارد که برخي از آن ها هم چونه افزونگي 12 معمول در پايگاه داده ها را با آزمون هاي مختلف آماري مي توان حل کرد. د)يکسان سازي فرمت ها: اين موضوع نيز يکي از مسايل مهم به هنگام تجميع داده هاست که به دليل اهميت آن و پنهان بودن زواياي آن از ديد داده کاوان؛ آن را به شکل مجزا مورد اشاره قرار داده ايم. براي درک پنهان و مشکل بودن تشخيص اين موارد بهتر است مثالي مطرح کنيم. به عنوان مثال در مورد فيلد تاريخ، فرمت هاي مختلفي براي ذخيره داده ها استفاده مي شود؛ که در صورت عدم دقت به اين مسأله، داده کاوي، اثربخشي لازم را به دنبال نداشته و بازسازي انباره هاي داده ساخته شده نيز،هزينه بالايي به دنبال خواهد داشت. راه حل اين مشکل عموماً در گرو درک داده هاي موجود در پايگاه هاي مختلف، از قبل تجميع آن هاست. ه) تصحيح داده هاي ناسازگار: اين مشکل مربوط به تناقض در داده ها بوده و از جمله مواردي است که نيازمند تجربه و صرف وقت بسيار است. به عنوان مثال وجود در فيلد تاريخ تولد و سن مربوط به يک مشتري خاص، در صورتي که همخواني لازم را نداشته باشد، ناسازگاري محسوب مي شود. اين گونه خطاها ممکن است به دليل استفاده از منابع مختلف داده و در زمان ترکيب دو منبع مختلف از داده ها روي دهد. اما مشکل عمده اي که با آن مواجه مي شويم و تشخيص آن بسيار مشکل است؛تعيين ناسازگاري هاي نهفته است. به عنوان مثال اگر به دنبال کشف الگو در مورد مسائل مربوط به هتل داري باشيد و قيمت مربوط به هتل هاي دنيا را از منابع مختلف جمع آوري کنيد، جداي از بحث تبديل نرخ ها و رفع ناسازگاري مربوط به مسايل خاص ارزي هر کشور، باز هم قيمت هتل ها نمي تواند ملاک مناسبي باشد؛ چرا که لازم است تا خدماتي همچون، صبحانه رايگان، استخر و ساير خدماتي را که در جاهاي مختلف به شيوه هاي مختلف ارايه مي شود، مد نظر داشت. به عبارتي قيمت هر شب اقامت در هتل در کنار نوع، شيوه و مقدار ارايه خدمات جانبي آن معنا پيدا مي کند. روش عمده و اصلي در حل ناسازگاري ها درک ماهيت داده ها است. اما در مواردي نيز ناسازگاري ها را که حاصل تجميع چند منبع مختلف بوده و بيانگر افزونگي داده هاست؛ مي توان با کمک روش هاي آماري بر طرف کرد. و) مواجهه با داده هاي نويز؛ داده هاي پرت؛ و هموار کردن اغتشاشات داده ها: قبل از هر چيز ديگر در اين جا لازم است تا تفاوت بين داده هاي نويز و داده هاي پرت14 را درک کنيم. اين تفاوت در اين نکته است که داده هاي نويز در اثر خطاهاي تصادفي بروز مي کنند. از جمله عواملي که سبب بروز داده نويز مي شود؛ مي توان به موارد زير اشاره کرد: *استفاده از ابزارهاي معيوب جمع آوري داده *مسائا و مشکلات حين ورود داده *محدوديت فناوري. قبل از بيان روش هاي مواجهه با اين گونه اغتشاشات داده اي، به ياد داشته باشيد که تشخيص نويز يا پرت بودن مهم تر از حل اين مشکل است! تشخيص اشتباه همواره درمان اشتباه به همراه دارد. از اين رو بايستي مطمئن شد که اولاً آن چه گمان مي کنيم مثلاً داده نويز است؛ واقعاً داده نويز باشد تا مبادا به عنوان انجام اصلاح در داده، داده اي با ارزش را تغيير دهيم. براي مواجهه با داده نويز و هموار کردن داده ها، روش هاي مختلفي وجود دارد، که از جمله مي توان به گسسته سازي 15 داده ها، رگرسيون، خوشه بندي و روش هاي ترکيبي بازرسي ماشين و انسان 16 اشاره کرد. البته برخي از اين روش ها، هم چون استفاده از رگسيون و خوشه بندي در داده هاي پرت نيز به کابرد دارد. از اين رو آن ها را تنها يک مرتبه توضيح مي دهيم. تلخيص توصيفي داده ها: نتايج حاصل از تلخيص توصيفي داده ها مي تواند به شکل گرافيکي درآمده و درک و توصيف داده ها را ميسر سازد. از جمله گراف هايي که براي نمايش گرافيکي تلخيص توصيفي داده ها استفاده مي شود مي توان به؛ هيستوگرام، چندک18،چندک چندک، نمودارپراکندگي نمودار لويس 19 ،نمودار جعبه 20 ،نمودار ميله اي اين ها اشاره کرد. نرم افزارهاي مختلف آماري بسياري از نرم افزارهاي کاربردي داده کاوي با فراهم کردن امکان نمايش گرافيکي داده هاي توصيفي تلخيص شده، در عمليات آماده سازي داده ها سهيم شده اند. گسسته سازي: هدف از اين روش آن است که داده ها را بر حسب قواعدي در دسته بندي هايي قرار دهيم؛ و دسته اي را که تعداد داده هاي موجود در آن بسيار کم باشد، کنار مي گذاريم. توجيه آن است که اين داده ها با ديگر داده ها تفاوت داشته و بنا به اشتباهاتي به وجود آمده اند. فراموش نکنيم که اين روش نبايستي حذف نمونه هاي ارزشمند را در تشخيص الگوها به همراه داشته باشد. از اين رو تأکيد مي کنيم که تشخيص نويز يا پرت بودن داده؛ از حل مشکل آن مهم تر است. رگسيون: رگسيون تنها روشي است که در صورت مهيا بودن شرايط استفاده، علاوه بر مشخص نمودن داده مغشوش براي آن مقدار هم پيشنهاد مي دهد. رگسيون بر روي تعداد مختلف ويژگي قابل اجراست. در صورتي که بر روي دو محور متعامد تنها دو ويژگي را در نظر داشته باشيم خروجي رگسيون برازش خطي براي تطبيق نقاط اين دو ويژگي است که به آن رگسيون خطي مي گويند. در صورتي که تعداد بيشتري متغير و با انواع ارتباط خطي و غير خطي داشته باشيم رگسيون ما يک رگسيون چند متغيره و يا غير خطي خواهد بود. قبل از استفاده از روش رگسيون بهتر است تا ويژگي هايي را که پيش بيني کننده خوبي براي متغير وابسته هستند؛ انتخاب کنيم. اين کار يا بر اساس نظر خبره و يا به کمک تست هاي مختلف آماري از قبيل تست هاي جهت و ميزان همبستگي صورت مي گيرد. مسأله مهم براي استفاده از رگسيون آن است که اين روش به داده هاي پرت حساس است. از اين رو مي توان با تعيين اوليه برخي نقاط پرت توسط اين روش يا هر روش ديگر و حذف آن ها دوباره رگسيون را تکرار کرد تا در حرحله تعدادي داده مغشوش مشخص و مقادير پيش بيني شده آن با نظر خبره تأييد گردد. نکته مهم ديگر آن که، دامنه استفاده از رگسيون محدود به داده هاي عددي نيست و با انجام مقدماتي مي توان براي داده هاي گسسته طبقه اي و ترتيبي نيز مورد استفاده قرار گيرد. از اين قبيل موارد ميتوان به رگسيون لجستيک و پواسون اشاره کرد که بيان جزييات مربوط به آن ها در اين مقوله نمي گنجد. خوشه بندي: از خوشه بندي نيز مي توان براي تعيين داده ها و خوشه هايي که مي تواند پرت بوده و يا براي مسأله مورد بررسي ما کاربرد نداشته باشد استفاده کرد. به عبارتي يکي از کاربردهاي خوشه بندي تعيين داده هاي فضاي مسأله مورد بررسي است. همان گونه که مي دانيد در خوشه بندي، مجموعه اي از داده ها که بر اساس ويژگي هاي مختلف بيشترين شباهت دارند در کنار يکديگر قرار مي گيرند. همان گونه که در شکل زير نيز مي بينيد؛ برخي داده ها بيرون خوشه ها قرار گرفته و مي توان آن ها را کنار گذارد. البته همواره بايستي احتياط هاي لازم را مد نظر داشت.
.JPG)
نتيجه گيري در اين مقاله، موضوع آماده سازي داده ها براي عمليات داده کاوي مورد توجه قرار گرفت. اهميت اين موضوع سبب شده تا بسياري نتايج ار داده کاوي را تنها در صورتي قابل اعتنا بدانند که از پيش پردازش مناسبي برخوردار باشد. موضوعات مختلفي براي انجام آماده سازي داده ها وجود دارد. از جمله اين موضوعات، پاک سازي داده ها، کاهش داده ها، کاهش ابعاد و مواردي از اين قبيل است. هر يک از موضوعات مطرح شده در پيش پردازش داده ها داراي مفاهيم و تکنيک هاي اجرايي مختلفي است که نيازمند تشريح و تفصيلي گسترده است. از اين در اين مقاله موضوع پاک سازي داده ها، انواع مشکلات و روش هاي مواجهه با آن ها مورد توجه قرار گرفت و بررسي ساير موارد به مقالات آتي موکول شد. با اين وجود، به کارگيري عملي اين موارد؛ نيازمند کسب تجربه و تکرار است. منابع: 1-Data Mining: Concepts and Techniques on the base of jiawei han lecture materials, PHD. T.shatovskaya software department PhD.T.shatovskaya software department 2-Data Preparation , Part 1: Exploratory Data Analysis&Data Cleaning, Missing Data , CAS 2007 Ratemaking Seminar ,Louise Francis, FCAS , Francis Analytics and Actuarial Data Mining, Inc. www.data-mines.com , [email protected] 3-Data Mining: Concepts and Techniques, San Francisco,CA:Morgan Kaufmann, Han, j ;Kamber , M.(2006 4- Chapter 3.Data PreParation and Screening, in Principles and Practice of Structural Equation Modeling, NY:Guilford Press,R.B. Kline, 2005,pp.45-62 5-http://healthdata.tbzmed.ac.ir/statistics/online%20education/chart/chart3.htm 6-http://www.wisegeek.com/what-is-data-scrubbing.htm 7-Spatial data mining implementation Alternatives and performances Nadjim Chelghoum-arine Zeitouni PRISM Laboratory, University of Versailles- France 8-IMPROVING DATA INTEGRATION FOR DATA WAREHOUSE:A DATA MINING APPROACH Kalinka Mihaylova Kaloyanova "St.Kliment Ohridski" University of Sofia, Faculty of Mathematics and Informatics Sofia 1164,Bulgaria [email protected], 2005 9-Data Mining: Concepts, Models, Methods, and Algorithms, Mehmed Kantardzic , John Wiley & Sons,2003,Chapter 2AND CHAPTER 3: Preparing the Data (Footnotes) 1-Data Mining 2-Text Mining 3-Web Mining Knowledge Mining 5-Data Preparation 6-Pre Proccessing 7-No quality data, no quality mining results 8-Garbage in Garbage Out 9-Missing Completely at Random (MCAR 10-Missing at Random 11-No Ignorable Missing Data (NMD 12-Redundancy 13-Inconsistent Data 14-Outlier 15-Binning or Discretization 16-Combined Computer and Human Inspection 17-Descriptive data summarization 18-Quantile 19-Loess Curve 20-Box Plot ماهنامه ي رايانه شماره 188
این صفحه را در گوگل محبوب کنید

-