

تبلیغات
تبلیغات متنی
آموزشگاه آرایشگری مردانه شفیع رسالت
دکتر علی پرند فوق تخصص جراحی پلاستیک
بهترین دکتر پروتز سینه در تهران
محبوبترینها
راهنمای انتخاب شرکتهای معتبر باربری برای حمل مایعات در ایران
چگونه اینورتر های صنعتی را عیب یابی و تعمیر کنیم؟
جاهای دیدنی قشم در شب که نباید از دست بدهید
سیگنال سهام چیست؟ مزایا و معایب استفاده از سیگنال خرید و فروش سهم
کاغذ دیواری از کجا بخرم؟ راهنمای جامع خرید کاغذ دیواری با کیفیت و قیمت مناسب
بهترین ماساژورهای برقی برای دیسک کمر در بازار ایران
بهترین ماساژورهای برقی برای دیسک کمر در بازار ایران
آفریقای جنوبی چگونه کشوری است؟
بهترین فروشگاه اینترنتی خرید کتاب زبان آلمانی: پیک زبان
با این روش ساده، فروش خود را چند برابر کنید (تستشده و 100٪ عملی)
خصوصیات نگین و سنگ های قیمتی از نگاه اسلام
صفحه اول
آرشیو مطالب
ورود/عضویت
هواشناسی
قیمت طلا سکه و ارز
قیمت خودرو
مطالب در سایت شما
تبادل لینک
ارتباط با ما
مطالب سایت سرگرمی سبک زندگی سینما و تلویزیون فرهنگ و هنر پزشکی و سلامت اجتماع و خانواده تصویری دین و اندیشه ورزش اقتصادی سیاسی حوادث علم و فناوری سایتهای دانلود گوناگون
مطالب سایت سرگرمی سبک زندگی سینما و تلویزیون فرهنگ و هنر پزشکی و سلامت اجتماع و خانواده تصویری دین و اندیشه ورزش اقتصادی سیاسی حوادث علم و فناوری سایتهای دانلود گوناگون
آمار وبسایت
تعداد کل بازدیدها :
1867186612













معماری Fermi شرکت Nvidia
واضح آرشیو وب فارسی:راسخون:

معماری Fermi شرکت Nvidia

بیانیه های اخیر Nvidia در رابطه با معماری GPU جدید این شرکت که تحت عنوان Fermi شناخته می شود، بیشتر به عملکرد بالا در حوزه Computing می پرداختند، تا عملکرد آن در بازیها. با اینحال، ویژگیهای جدید و بهبود یافته Fermi در عین حال شواهدی را در رابطه با آنچه که می توانید در حوزه اجرای بازیها از GPU بعدی Nvidia انتظار داشته باشید، فراهم می کنند. Nvidia معماری Fermi خود را در اواخر سال 2009 معرفی کرد و بخش عمده ای از مباحث اولیه در رابطه با Fermi بر روی Tesla متمرکز بودند که محصولات High Performance Computing(HPC) شرکت Nvidia را در بر می گیرد. Nvidia تأثیر GPU جدید خود بر بازیها و گرافیکهای 3 بعدی را به همراه اطلاعات مشروح درباره مشخصات تراشه های Fermi در نمایشگاه CES 2010 تشریح کرد. با اینحال، ما در این مقاله بر جنبه هائی از اطلاعات مربوط به Fermi تکیه خواهیم داشت که به Tesla و HPC مربوط می شوند، هرچند که بخش عمده ای از این اطلاعات در مورد GPUهای عمومی Fermi نیز صادق خواهند بود. مسیر Fermi واحد پردازنده گرافیکی GPU(Fermi) وعده می دهد تا مسیری که Nvidia با معماری G80 خود آغاز کرده و با GT200 ادامه داده بود را دنبال کند: یک GPU که با قدرت محاسباتی و قدرت گرافیکی بطور تقریباً یکسانی رفتار نماید. GPUهای Fermi از ویژگیهای زیر برخوردار خواهند بود: - نزدیک به 3 میلیارد ترانزیستور - پشتیبانی از حداکثر 6 گیگابایت حافظه GDDR5 DRAM -پشتیبانی از DirectX 11 - 512 هسته CUDA - پشتیبانی از زبان برنامه نویسی C+

- ECC(Error Correction Codes) بر روی اینترفیسهای حافظه Tom R.Halfhill تحلیلگر ارشد In-Stat در گزارش Microprocessor Report این مجموعه می گوید:« بعضی از این ویژگیها در عین حال برای چیزی که Nvidia آن را GPU Computing می نامد و عملاً معادل HPC برای مصرف کنندگان عام خواهد بود نیز مفید هستند». معماری جدید Fermi تنها چند سال بعد از معماری GT200 معرفی شده است. David Patterson استاد علوم کامپیوتر دانشگاه برکلی کالیفرنیا می گوید:« Nvidia از یک تاریخچه نسبتاً طولانی در ارائه معماریهای سلطه جویانه جدید در فواصل تقریباً 3 ساله برخوردار است. من خوشحالم که می بینم آنها بعضی از مشکلات موجود( نه تمام آنها) در زمینه افزایش سودمندی GPU برای کلاس گسترده تری از وظایف را برطرف نموده اند». معماری همانطور که قبلاً نیز اشاره کردیم، Fermi شامل 512 هسته CUDA(Compute Unified Device Architecture) می باشد. هر هسته CUDA یک عملیات عدد صحیح ( Integer) عملیات اعشاری ( Floating Point) با دقت واحد( Single-Precision) را در هر سیکل کلاک برای هر رشته ( Thread) اجرا می کند. به این ترتیب، یک سطح فرکانسی 1/5 گیگاهرتزی به معنای حداکثر نرخ عملیاتی معادل با 1/5 ترافلاپس( TELOPS) برای Fermi خواهد بود.

512 هسته CUDA در داخل SM (Streaming Processor) 16 سازماندهی شده اند. هر SM( که در شکل [1] بصورت ستونهای عمودی عریض نشان داده شده اند) حاوی 32 هسته CUDA( که تحت عنوان پردازنده های CUDA نیز شناخته می شوند) می باشد که 4 برابر بیشتر از تعداد هسته های CUDA موجود در SMهای پیاده سازی شده در طراحیهای GPU قبلی شرکت Nvidia است. در داخل هر هسته CUDA، یک واحد منطقی محاسبات عدد صحیح ( INT) و یک واحد منطقی محاسبات اعشاری( FPU) قرار دارد.

این SM 16 یک ناحیه حافظه کاشه L2 768 کیلوبایتی اشتراکی را احاطه کرده اند. هر SM شامل یک ناحیه Wrap Scheduler و Dispatch، نواحی کاشه و فایلهای رجیستر است. در داخل هر SM، چهار ستون( دو ستون از هسته های CUDA، یک ستون LD/ST و یک ستون SFU) قرار گرفته اند که 32 هسته CUDA، LD/ST 16( واحدهای Load/Store) و SFU 4 ( واحدهای Special Functions) را در بر می گیرند. واحدهای Load/Store از محاسبات آدرسهای مبداء و مقصد برای 16 رشته در هر سیکل کلاک پشتیبانی می کنند. SFUها نیز انواع خاصی از دستورالعملها نظیر محاسبه کسینوس و یا جذر ریشه دوم را اجرا می نمایند. هر SFU می تواند یک دستورالعمل را برای هر رشته اجرا کند. هر SM گروه هائی متشکل از 32 رشته موازی را برنامه ریزی می کند که تحت عنوان Wrapها شناخته می شوند. در داخل هر SM، دو Wrap Scheduler و دو واحد Instruction Dispatch قرار گرفته اند. این پیکربندی می تواند دو Wrap را بطور همزمان اجرا نماید که دو ستون از 4 ستون را اشغال می کنند. برای مثال، اگر یک دستورالعمل اعشاری Double Precision(64-Point) صادر گردد، هر دو ستون هسته CUDA را اشغال خواهد نمود. به این ترتیب دو ستون دیگر خالی خواهند ماند. Fermi شامل 6 کنترلر حافظه 64 بیتی است که داده ها را به هسته های CUDA می رسانند. هر کنترلر حافظه از GDDR5 DRAM پشتیبانی می کند که باعث می شود Fermi به اولین GPU سطح بالای Nvidia با قابلیت بهره گیری از حافظه GDDR5 تبدیل گردد. به این ترتیب می توان پیش بینی کرد که پهنای باند متراکم این ترکیب در Fermi تقریباً 30 درصد بالاتر از 8 کنترلر حافظه DDR3 در Geforce GTX 280 خواهد بود. یک برتری دیگر حرکت از GDDR3 به GDDR5 این است که استاندارد حافظه جدید پهنای باند بالاتری را برای هر پایه تأمین می نماید و این بدان معنی است که Fermi می تواند از یک اینترفیس حافظه کوچکتر( 384 بیتی) در مقایسه با اینترفیس حافظه 512 بیتی در GTX 280 استفاده کند. یک اینترفیس حافظه کوچکتر به معنای نیاز کمتر به مصرف برق عملیاتی بوده و در عین حال به پایه های کمتری نیاز دارد. اینترفیس میزبان بعنوان اتصال مابین GPU و CPU از طریق یک اینترفیس PCI-E 16 مسیره عمل می کند که باید با حداکثر نرخ 8 گیگابایت بر ثانیه عمل نماید. GigaThread یک برنامه ریز ( Scheduler) عمومی به حساب می آید که بلوکهای رشته را در بین Schedulerهای داخل هر SM توزیع می کند. در داخل واحد GigaThread پردازنده گرافیکی Fermi، یک HTS(Hardware Thread Scheduler ) قرار گرفته است. HTS هزاران رشته فعال بر روی GPU را مدیریت نموده، کار را مابین SMهای قابل دسترسی توزیع کرده و سوئیچهای مضمون را مدیریت می کند. با پیاده سازی نگهداری برنامه زمانبندی بصورت سخت افزاری و از طریق HTS( بجای پیاده سازی نرم افزاری در پیکربندیهای قدیمی)، توسعه دهندگان نرم افزارهای کاربردی می توانند نرم افزارهائی را طراحی کنند که بر روی GPUهائی با تعداد دلخواهی از SMها اجرا شوند. زمانبندی رشته ها با GigaThread با Gigathread Thread Scheduler در Fermi، یک موتور توزیع کار عمومی در ابتدا بلوکهای رشته را در سطح تراشه زمانبندی نموده و آنها را مابین SMها توزیع می کند. سپس، Wrap Scheduler در سطح SM، Wrapهائی با حداکثر 32 رشته را در میان واحدهای اجرائی توزیع می نماید. این فرایند کاملاً به پیکربندی GPUهای قبلی شباهت دارد، اما بهسازیهای Fermi در GigaThread اساساً در دو حوزه خودنمائی می کنند:

-Context Switching: ایده سوئیچ مضمون در CPUها و GPUها بطور مشابهی عمل می کند. اساساً این نوعی Multitasking است که در آن هر برنامه بخشی از زمان منابع پردازنده را بدست می آورد. Fermi مدت زمان مورد نیاز برای سوئیچ مضمون را به کمتر از 25 میکروثانیه کاهش داده است که باعث بهبود کلی عملکرد می گردد. - اجرا همزمان کرنل: همانطور که در شکل [3] نشان داده شده است، تحت Fermi اگر یک برنامه مجبور باشد تعداد زیادی از کرنلهای کوچک را اجرا نماید، تمام آنها می توانند بطور همزمان بر روی GPU اجرا شوند که امکان بهره گیری بهتر از تمام منابع GPU را در مقایسه با پیکربندیهای قبلی فراهم می نماید. در عین حال، Context Switching نیز به اجرای همزمان کرنل کمک می کند. ریاضیات جدید احتمالاً جالبترین جنبه از معماری Fermi برای HPC، این نکته خواهد بود که از استاندارد حساب اعشاری جدید IEEE یعنی 754-2008 استفاده می کند( بجای استاندارد قدیمی که با نام 754-1985 شناخته می شد). استاندارد جدید شامل دستورالعمل FMA(Fuse Multi-Add) می باشد. بعلاوه، اعداد صحیح 32 بیتی برای عملیات ضرب نیز بخشی از ALU(Arithmetic Logic Unit) Fermi خواهند بود. در گذشته، ALU سخت افزار GPU به اعداد صحیح 24 بیتی محدود بود. دستورالعمل FMA بسیار مطلوب تر از دستورالعمل MAD(Multiply-Add) سابق خواهد بود زیرا FMA هر دو عملیات ضرب و جمع را در یک مرحله واحد انجام می دهد که به این ترتیب امکان گرد کردن دقیق تری را فراهم می سازد. دستورالعمل MAD گاهی باعث کاهش دقت در مرحله اضافی خود می گردید. Fermi اختصاصاً برای کاربردهای محاسباتی با دقت مضاعف( Double-Precision) نظیر شیمی کوانتومی و جبر خطی طراحی شده است که باز با گرایش به سمت HPC انطباق دارند. حداکثر 16 عملیات ضرب/ جمع می توانند در هر سیکل کلاک بر روی هر SM اجرا شوند که تقریباً 4 برابر عملیات انجام شده بر روی معماری GT 200 خواهد بود. دقت 32 بیتی عملیات اعشاری IEEE یک ویژگی جدید دیگر در Fermi، پشتیبانی از آخرین استاندارد دقت اعشاری IEEE، یعنی 754-2008 است. ویژگی جدید اصلی در این استاندارد، پشتیبانی از اعداد Subnormal است، اعداد کوچکی که تقریباً معادل صفر هستند. IEEE استاندارد 754-2008 را در آگوست سال 2008 منتشر کرد. این اولین بروز رسانی استاندارد اعشاری از زمان انتشار 754-1985 در سال 1985 به بعد بود. فرآیند بازنگری که به انتشار 754-2008 منتهی گردید، به 7 سال کار مداوم نیاز داشت.
Floating Point( ممیزی شناور و یا همان اعشاری) یک سیستم بیان رشته ای از ارقام است که معادل یک عدد منطقی هستند. عبارت شناور (Floating) به جابجائی ممیز اعشاری نسبت به اعداد صحیح در یک عدد منطقی اشاره دارد. شما می توانید آن را بعنوان یک علامت علمی برای محاسبات در نظر بگیرید. توانائی یک GPU برای انجام سریع و دقیق عملیات اعشاری، از اهمیت بالائی در تعیین سطح عملکرد GPU برخوردار است. در گذشته، اینگونه اعداد Subnormal معادل صفر در نظر گرفته می شدند که به افت دقت محاسبات منتهی می گردید. با اینحال، افت دقت مذکور تحمل می شد زیرا اینگونه اعداد بصورت نرم افزاری اداره می شدند و گاهی اوقات به هزاران سیکل محاسباتی نیاز داشتند که با یک تأثیر منفی بر عملکرد همراه بود. اکنون Fermi اعداد Subnormal را بصورت سخت افزاری اداره می کند که مشکلات عملکردی را از بین خواهد برد.اجازه بدهید به یک مثال برای استفاده از دقت اعشاری جدید در گرافیکهای کامپیوتری اشاره کنیم: - یک تابع متداول شامل دو عملیات است: ضرب دو عدد و جمع کردن یک عدد سوم( A x B+C=Result). - در گذشته، دستورالعمل multiply-add)MAD) هر دو عملیات را در داخل یک سیکل واحد انجام می داد. با اینحال نتیجه ضرب باید کوتاه می شد که گاهی اوقات با خطاهائی در گرد کردن همراه بود. - Fermi از دستورالعمل fused multiply-add(FMA) استفاده می کند که امکان بهره گیری از دقت کامل( بدون کوتاه سازی) را در مرحله ضرب فراهم می سازد و در عین حال سطح عملکردی خود را نیز حفظ می نماید. برای مثال الگوریتمهای مورد استفاده برای راندوی اشکال هندسی با تقاطع ظریف، بطور قابل ملاحظه ای از دقت تأمین شده در FMA سود خواهند برد. بازیها یا HPC بعضی از کاربران در مجموعه طرفداران بازیها از این موضوع که Nvidia تصمیم گرفته بود بیشتر بر گزینه های Tesla و HPC مبتنی بر GPU جدید خود تکیه نماید، ناامید شده بودند. بدیهی است که GPUهای مخصوص بازیها و کاربردهای گرافیکی در حال حاضر بخش اعظم تجارت Nvidia را به خود اختصاص داده اند، در حالیکه HPC فعلاً تنها بخش کوچکی از درآمد این شرکت را تشکیل می دهد. Nvidia امیدوار است HPC نهایتاً تا سطح یک حوزه درآمد ساز بزرگتر رشد کند، اما Halhill معتقد است که تأکید بر پیاده سازی قابلیتهای HPC در GPUها می تواند این شرکت را با تصمیم گیریهای دشواری در مسیر خود مواجه سازد. او می گوید:« با نگاه به آینده، من پیش بینی می کنم که Nvidia به نوآوریهای سلطه جویانه و جسورانه خود ادامه خواهد داد. با اینحال، GPUها احتمالاً در مسیر خود با یک دو راهی مواجه خواهند شد. در یک نقطه، ویژگیهای طراحی شده برای HPCها احتمالاً به مانعی برای GPUهای در نظر گرفته شده برای مصرف کنندگان عام تبدیل خواهند گردید. برای مثال، GPUها برای اجرای بازیها و بسیاری از نرم افزارهای کاربردی دیگر در حوزه مصرف کنندگان عام به ECC نیازی ندارند». Halfhill ادامه می دهد:« احتمالاً Nvidia روزی مجبور خواهد شد تا GPUهای جداگانه ای را برای حوزه های HPC و بازار مصرف کنندگان عام طراحی نماید. پروژه های طراحی جداگانه می توانند هزینه بیشتری را بر این شرکت تحمیل نموده و تا حدودی مزیت استفاده از بازار بزرگ مصرف کنندگان عام برای کمک به هزینه های توسعه GPUهای مخصوص HPCها را خنثی کنند». GPU در مقابل CPU حتی اگر GPUهای Fermi و سکوی Tesla شرکت Nvidia با پذیرش کامل جامعه HPC مواجه شوند، چنین انتقالی به معنای پایان کار CPUها نخواهد بود. Halfhill در این زمینه می گوید:« ما به هیچوجه به زمان منسوخ شدن CPUها توسط GPUها نزدیک نیستیم. CPU هنوز پادشاه سیستمهای کامپیوتری است و این موقعیت را در آینده قابل پیش بینی حفظ خواهد کرد. قدم بعدی، ادغام CPU و GPU بر روی یک تراشه واحد است که از قبل در سیستمهای Embedded نظیر تلفنهای سلولی اتفاق افتاده و بزودی با تراشه Larrabee شرکت اینتل و معماریهای Fusion شرکت AMD در حوزه PC اتفاق خواهد افتاد». برای آن دسته از خوانندگان که با این حوزه آشنائی ندارند، باید بگوئیم که CPU دارای مزایای بخصوصی است، مثلاً برای آن دسته از نرم افزارهای کاربردی که به تعداد محدودی از رشته های پردازشی نیاز دارند و یا شامل ترکیب بزرگی از عملیات گوناگون هستند. از سوی دیگر، GPUها در آن دسته از نرم افزارهای کاربردی که به رشته های متعددی با توالیهای طولانی از دستورالعملها نیاز دارند، دارای برتری می باشند. همانطور که Patterson اشاره می کند، GPUها در هنگام مقایسه با CPUها هنوز باید چالشهای مختلفی را پشت سر بگذارند. برای مثال، GPUها باید با حجم نسبتاً پائین حافظه GPU و ناتوانی در انجام I/O مستقیم به حافظه GPU مقابله نمایند. Patterson می گوید:« ما هنوز به منسوخ شدن CPUها نزدیک نشده ایم، زیرا GPUها با نقطه ضعفهای متعددی مواجه هستند و مشخص نیست که چقدر طول خواهد کشید تا شاهد برطرف گردیدن این نقطه ضعف ها باشیم». پیکربندی حافظه On-chip از آنجائیکه الگوریتمها و نرم افزارهای کاربردی محاسباتی، همگی رفتار نسبتاً متفاوتی با حافظه GPU دارند، Fermi می تواند حافظه خود را برای انطباق با نیازهای یک نرم افزار کاربردی پیکربندی نماید. صرفنظر از اینکه الگوریتم یا نرم افزار کاربردی به حافظه اشتراکی بیشتری نیاز دارد یا کاشه L1 بیشتر، Fermi می تواند حافظه On-chip خود را به همان صورتی که برنامه نویس مشخص می کند مجدداً برای انطباق با این نیازها پیکربندی نماید. معماريهاي قبلي، 16 کيلوبايت حافظه اشتراکي را براي هر SM در بر مي گرفتند، اما Fermi به 64 کيلوبايت حافظه On-chip براي هر SM مجهز است که مي تواند بصورت 16 کيلوبايت حافظه اشتراکي و 48 کيلوبايت کاشه L1 ( و يا بالعکس) تقسيم گردد. - حافظه اشتراکي: به گفته Nvidia، برنامه اي که به استفاده گسترده از حافظه اشتراکي نياز دارد، مي تواند بر روي Fermi سه برابر سريعتر اجرا شود زيرا اين تراشه 48 کيلوبايت حافظه اشتراکي را در مقايسه با 16 کيلوبايت پيکربنديهاي قبلي در دسترس برنامه قرار مي دهد. با سه برابر شدن مقدار حافظه اشتراکي در مقايسه با معماريهاي قبلي، نرم افزارهاي کاربردي معين مي توانند از حافظه اشتراکي اضافي بعنوان کاشه تحت مديريت نرم افزار استفاده کنند که باعث بهبود عملکرد خواهد شد. -کاشه L1: براي ساير برنامه ها، دسترسي به 48 کيلوبايت حافظه کاشه L1 امکان اجراي سريعتر در مقايسه با پيکربنديهاي قبلي را فراهم مي سازد، زيرا برنامه ها مجبور نخواهند بود دائماً به DRAM دسترسي پيدا کنند. Fermi داراي 768 کيلوبايت کاشه L2 يکپارچه مي باشد که تمام انواع درخواستها(Texture، Store و Load) را اداره مي نمايد. بررسی اجمالی Hydra 200 موتور Hydra از طریق سخت افزار ASIC(Application-Specific Integrated Circuit) به همراه یک درایور نرم افزاری کار می کند. تولیدکنندگان مادربرد، تراشه Hydra را مابین پل شمالی CPU و GPUها نصب می کند. Hydra از ترکیبی از سخت افزار و نرم افزار استفاده می کند که Lucid برای ایجاد فناوری Multi-GPU خود ایجاد نموده است. پرسنل Lucid به 60 نفر می رسند که هر دو گروه مهندسین نرم افزار و سخت افزار را در بر می گیرند و در حوزه هائی نظیر گرافیکهای 3 بعدی، طراحی تراشه، شبکه سازی و سایر مهارتها، تخصص دارند. به گفته Remez، برای Lucid بسیار مهم است که کارکنانی با سوابق فنی متنوع را در اختیار داشته باشد زیرا Hydra باید کارهای بسیار مختلفی را انجام دهد. او می گوید:« تراشه باید انبوهی از داده ها را اداره نماید که از همه جا می آیند».
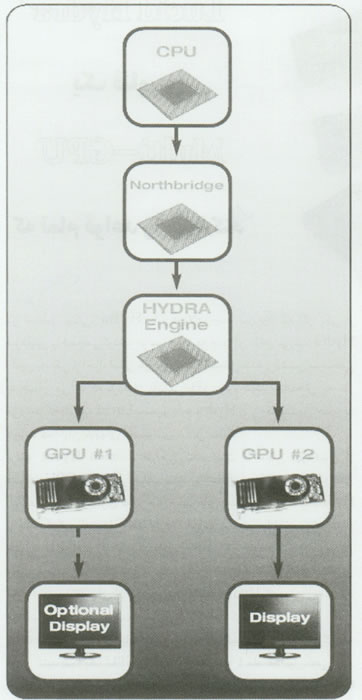
Hydra در مسیر Callها و دستورالعملهائی که از CPU به GPUها فرستاده می شوند، قرار می گیرد( نظیر جریانهای فرمان DirectX یا OpenGL). سپس، کارهائی که باید انجام شوند را دقیقاً تعیین نموده سازماندهی می کند. Remez در این رابطه می گوید:« ایجاد یک فریم واحد با هزاران آبجکت و وظیفه مختلف سر و کار دارد. فرض کنید که من می توانم هریک از این وظایف را با آگاهی از زمانی که لازم دارند، حافظه مورد نیاز آنها و سایر موارد مشابه شناسائی نمایم و همچنین تصور کنید که من GPU 1000 برای انجام 1000 وظیفه در اختیار دارم. اگر بتوانم بطور همزمان یک وظیفه را به هر GPU محول کنم، می توانم تمام نتایج را بصورت بلادرنگ ترکیب نمایم». او اضافه می کند:« در دنیای واقعی، ما برای انجام همین کار تلاش می کنیم، اما هر وظیفه به سایر وظایف وابسته است. تمام این وظایف به یکدیگر ارتباط دارند. پس چگونه می توانیم این مشکل را حل کنیم؟ ما یک وظیفه واحد را بر روی GPUهای متعددی مقیاس دهی می نمائیم». سپس Hydra با استفاده از داده های تاریخی مرتبط با سطوح عملکردی GPUهای نصب شده، وظایف را مابین GPUها توزیع کرده و تلاش می نماید تا یک بار کاری را برای آنها تأمین کند که قابلیتهای هر GPU برای ایجاد یک جریان کاری روان را به حداکثر برساند. تراشه های Hydra کار با GPUها را بطور خودکار اداره نموده و نحوه تقسیم بار کاری را تعیین می کنند. اگر به هر دلیلی Hydra نتواند پیکربندی Multi-GPU را با یک بازی خاص و یا یک ترکیب بخصوص از GPUها بکار بیندازد، بطور خودکار به یک سطح پائینتر انتقال یافته و سیستم را به یک پیکربندی Single-GPU بر می گرداند. کاربر به هیچوجه مجبور نیست تنظیمات سیستم را برای انجام اینکار تغییر دهد. همانطور که در شکل [1] مشاهده می کنید، خود GPUها مستقیماً با یکدیگر ارتباط ندارند. تمام کار اشتراک گذاری داده ها در بین GPUها از طریق تراشه Hydra انجام می شود. هرگونه داده ای که مابین CPU و GPUها به اشتراک گذاشته می شود نیز باید از تراشه Hydra عبور کند. این پیکربندی به تولیدکنندگان مادربردها اجازه می دهد تا انعطاف پذیرترین گزینه های طراحی را ایجاد نمایند. از آنجائیکه سیستم Hydra به مقیاس دهی GPUها اختصاص یافته است و همچنین به دلیل آنکه هیچ منطق پردازش گرافیکی بر روی تراشه Hydra اتفاق نمی افتد، شیوه های متداولی که در حال حاضر برای تقسیم بار کاری مابین یک جفت GPU مورد استفاده قرار می گیرند( نظیر فریمهای یک در میان و یا تقسیم فریم) را بهبود می بخشد. - فریم یک در میان(Alternate Frame): در تکنیک فریمهای یک در میان، هر GPU به نوبت فریمها را بطور یک در میان راندو می نماید. این تکنیک گاهی اوقات باعث ایجاد مشکلات تأخیری می گردد، مگر آنکه هر فریم به مدت زمان مساوی برای پردازش نیاز داشته باشد. با اینحال هنگامیکه GPUها یکسان نباشند، تکنیک فریمهای یک در میان بخوبی کار نخواهد کرد. - تقسیم فریم: تعداد کمی از معماریهای Dual-GPU هنوز از تکنیک Split-Frame استفاده می کنند. با این تکنیک، هر GPU نمایش یک بخش معین از تصویر را اداره می نماید. تکنیک تقسیم فریم باعث کاهش مشکلات مربوط به گلوگاه های سایه زنی پیکسل (Pixel Shading) می گردد، اما از آنجائیکه هر GPU باید کل تصویر را در ناحیه حافظه خود ذخیره کند، استفاده از این تکنیک می تواند باعث ایجاد گلوگاه های حافظه گردد. معماری موتور Hydra موتورHydra شرکت Lucid اولین تراشه سیلیکونی است که RTDP(Real-Time Dedicated Processing) را پیاده سازی می کند. موتور Hydra هر فریم را پیش از راندو تجزیه و تحلیل نموده و سپس وظایف مربوط به آن را براساس قابلیتها و دسترس پذیری هریک از GPUهای داخل سیستم، مابین آنها توزیع می کند. استفاده از این نوع سیستم به موتور Hydra امکان می دهد تا به خوبی با GPUهائی در سطوح مختلف قدرت راندو کار کرده و آنها را بهینه سازی نماید. با آنالیز پیش از موقع هر فریم، موتور Hydra می تواند گلوگاه ها را به حداقل رسانده و تأخیر را کاهش دهد.
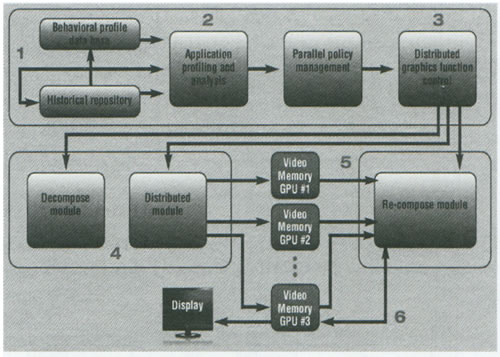
شکل [2] موتور Hydra را نمایش می دهد. اجازه بدهید یک مثال از نحوه کار تراشه Hydra را با استفاده از این شکل بررسی کنیم. 1- موتور توزیع Hydra اطلاعات را هنگام انتقال آنها به CPU توسط بازی، می خواند. می توانید تصور کنید که Hydra دستورالعملها و Calهای DirectX و OpenGL که توسط بازی برای GPUها فرستاده می شوند را استراق سمع می نماید. 2- Hydra اطلاعات را تجزیه و تحلیل کرده، آنها را به وظایف مشخصی تقسیم نموده و سپس به GPUها می فرستد. یک وظیفه می تواند تقریباً هرچیزی باشد، از یک افکت نورپردازی خاص گرفته تا یک ترسیم یک آبجکت معین. Hydra از الگوریتمهای انحصاری برای کامپایل وظایف ( Application profiling and analysis) استفاده می کند. 3- پس از مشخص شدن وظایف، تراشه Hydra وظایف را مابین GPها تقسیم می نماید. این تراشه از الگوریتمهای خود برای تقسیم بار کاری با یک روش« هوشمندانه» برای بهره گیری کامل از منابع و قابلیتهای هر GPU(Parallel policy management) استفاده می کند. تراشه Hydra بطور خودکار قابلیتهای هر GPU را بر حسب سطوح عملکردی تاریخی آن، تخمین می زند( Historical repository). با ادامه کار، Hydra معیارهای خود را براساس عملکرد بلادرنگ GPUها بروزرسانی می نماید( Behavioral prifile data base). 4- سپس Hydra داده ها را به GPUها می فرستد( از طریق ماجولهای Decompose و Distributed). 5- پس از آنکه کار GPUها به پایان رسید، داده ها را به تراشه Hydra بر می گردانند تا در آنجا کامپایل شوند( ماجول Recompose). 6- در نهایت، Hydra صحنه نهائی را به یکی از GPUها می فرستد که به نمایشگر متصل شده است. تاریخچه Lucid Lucid که نام رسمی آن LucidLogix می باشد، یک شرکت طراحی کننده نیمه هادی است که خودش دارای تأسیسات تولیدی نمی باشد و برای این منظور به تولیدکنندگان قراردادی تکیه دارد. پشتوانه مالی Lucid از مؤسساتی نظیر Giza Venture Capital، Genesis Parteners، Intel Capital و Rho Ventures تأمین می شود. دفتر مرکزی این شرکت در کالیفرنیا قرار گرفته و تاکنون بیش از 60 حق امتیاز و یا درخواست ثبت امتیاز را در اختیار دارد. Remez در این زمینه می گوید:« من و همکارم دکتر Reuven Bakalash شرکت Lucid را در اواخر سال 2003 راه اندازی کردیم. وقتی از راه اندازی صحبت می کنم، منظورم یادداشتهائی بر روی یک دستمال سفره در یک کافی شاپ است. اکثر ایده های ما چندان خوب نبودند، ولی ما یک ایده در اختیار داشتیم که به توسعه آن ادامه دادیم». ایده بهره گیری از یک طراحی Multi-GPU برای تأمین قدرت راندوی بیشتر( بجای کپی کردن فناوریهای چند هسته ای که تولیدکنندگان CPU از آنها حمایت می کردند) به نیروی محرکه Lucid تبدیل شد. همانطور که فناوریهای SLI شرکت Nvidia و CrossFire شرکت ATI نشان می دهند، Lucid بطور آشکارا تنها شرکتی نیست که گزینه ای Multi-GPU را ارائه می کند، اما Hydra اولین محصولی است که امکان استفاده از یک پیکربندی ترکیبی از GPUهای تولیدکنندگان متفاوت را فراهم می سازد. Remez می گوید:« ما خودمان را پیشتاز این حوزه در نظر گرفتیم. وقتی ما درباره این موضوع فکر کردیم، سیلیکون نمی توانست به رشد خود ادامه دهد. سیلیکون در هر چرخه تقریباً 33 درصد کوچکتر می شود، اما تعداد ترانزیستورهای داخل آن به بیش از دو برابر افزایش می یابد. راه حل صنعت برای این مشکل، تولید پردازنده های چند هسته ای بود. حتی پردازنده هائی که در پائین ترین سطح ارائه می شوند نیز دارای دو هسته خواهند بود». با در نظر گرفتن طبیعت پردازش گرافیکی، چندان شگفت آور نیست که GPUها از استفاده از هسته های متعدد اجتناب کرده اند. به گفته Remez، پیکربندی های چند هسته ای که CPUها در حال حاضر از آن استفاده می کنند بخوبی برای GPUها جواب نمی دهد زیرا راندوی گرافیکی به یک نوع راه حل متفاوت با آنچه که در CPUها کار می کند، نیاز دارد. او می گوید:« تفاوت بسیار زیادی مابین نقطه ای که گرافیکها امروزه در آن قرار گرفته اند و هدفی که ما می خواهیم به آن برسیم وجود دارد. راه حل چند هسته ای نمی تواند پاسخگوی نیازهای راندوی بازیها باشد. معماری چند هسته ای نمی تواند به این نیاز پاسخ دهد زیرا وظیفه راندوی بازیها یک وظیفه تک رشته ای با خط لوله ترتیبی است که از هسته های متعدد هیچ بهره ای نمی برد». فروش Hydra به گفته Remez، متقاعد نمودن تولید کنندگان مادربردها به استفاده از تراشه های Hydra بسیار آسانتر از چیزی است که احتمالاً فکر می کنید، البته این موضوع به شرکت تولید کننده نیز بستگی دارد. او می گوید:« اگر آنها با فناوری Multi-GPU آشنائی داشته باشند، فروش در یک مدت زمان کاملاً قابل قبول امکانپذیر خواهد بود. اما گذراندن محصولات مادربرد در تمام مسیر از یک پیش نمونه تا مرحله دسترس پذیری کاربران، چالش کاملاً متفاوتی به حساب می آید». یک ویژگی که Hydra را به یک گزینه مطلوب تبدیل می کند، این واقعیت است Lucid با تأمین اطلاعات انحصاری هیچگونه وابستگی به تولیدکنندگان مهم GPU ندارد. تراشه Lucid Hydra پیش از آغاز کار خود صرفاً نیاز دارد بداند که چه GPUهائی بر روی سیستم نصب شده اند( اطلاعاتی که به آسانی از طریق خود سیستم قابل دستیابی می باشد). Hydra هیچ نیازی به آگاهی از عملکردهای داخلی GPها ندارد. تراشه های Lucid با GPUها از طریق DirectX( از جمله DirectX 11) کار می کنند. Remez می گوید:« ما یک کانال باز با تمام فروشندگان GPU در اختیار داریم. ما درباره موضوعات بسیاری به مذاکره و گفتگو می پردازیم. اما هیچگونه اطلاعات تکنولوژیکی مابین ما رد و بدل نمی شود. هیچ تعامل مستقیمی بین ما و فروشندگان وجود ندارد». به گفته Remez، شرکت Lucid در یک وضعیت مشابه ارتباط و مذاکرات خود را با توسعه دهندگان بازیها حفظ می کند، اما این شرکت واقعاً به هیچ اطلاعات انحصاری از سوی شرکتهای تولیدکننده بازی نیاز ندارد. Hydra صرفاً دستورالعلمها را از بازیها می خواند و نیازی ندارد که عملکرد خود را بر حسب یک بازی بخصوص و یا GPUهای مورد استفاده تغییر دهد. Remez می گوید:« این مذاکرات تقریباً یک طرفه هستند. آنها از ما می پرسند که به چه چیزی از طرف ما نیاز دارید؟ و ما پاسخ می دهیم که هیچ چیز. سپس آنها می پرسند که پس چرا به اینجا آمده اید؟ ما هیچ چیزی برای ارائه مستقیم به توسعه دهندگان بازیها نداریم، پس این ملاقاتها بسیار عجیب به نظر می رسند. با اینحال، ما به این مذاکرات ادامه می دهیم زیرا می خواهیم با آنها ارتباط داشته باشیم». آزمایش و باز هم آزمایش با وجود آنکه Lucid تراشه های Hydra را در اصل برای علاقمندان بازیها در نظر گرفته است، اما واقعیت این است که تراشه های مذکور می توانند در هر نرم افزار کاربردی با گرافیکهای سنگین و یا هر پیکربندی چند نمایشگری مورد استفاده قرار گیرند. با اینحال، در حال حاضر آزمایشهای Lucid بر روی بازیها متمرکز است. به گفته Remez، آزمایش یک کار بسیار وقتگیر است، زیرا شرکت او تلاش می کند تا بازیهای متعددی را با صدها ترکیب احتمالی از GPUها آزمایش نماید. او می گوید که حتی با وجود آنکه Hydra با تمام ترکیبهای واجد شرایط GPUها کار می کند، اما مرحله آزمایش از اهمیت حیاتی برخوردار است. Remez می گوید:« با وجود آنکه این محصول برای کار با یک دامنه گسترده از نامهای تجاری GPUها طراحی شده است، وقتی شما به فرآیند توسعه محصولات نگاه می کنید، متوجه می شوید که ما نمی توانیم همه چیز را آزمایش نمائیم. کیفیت بصری، عملکرد و پایداری از اهمیت بسیار بالائی برخوردارند. ما هر کاری که بتوانیم را برای آزمایش این موارد انجام می دهیم. سپس، اعلام می کنیم که این بازیها برای این که ترکیبهای GPU « واجد شرایط» هستند. با اینحال، این بدان معنی نخواهد بود که سایر بازیها و یا سایر ترکیبهای GPU در این شرایط کار نمی کنند، بلکه صرفاً به معنای آن است که ما هنوز آنها را آزمایش نکرده ایم». در عین حال، علیرغم تعداد سرسام آور پیکربندیهای احتمالی برای آزمایش، Remez معتقد است که Hydra 200 با هیچیک از پیکربندیهائی که Lucid تاکنون برای آن آماده کرده، مشکلی نداشته است. مدلهای Hydra 200 3 مدل از Hydra 200 روانه بازار شده اند: LT22114 بعنوان تراشه سطح پائین، LT22102 بعنوان تراشه متوسط و LT24102 که تراشه سطح بالای خانواده به حساب می آید.
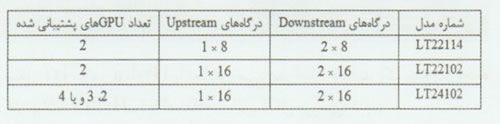
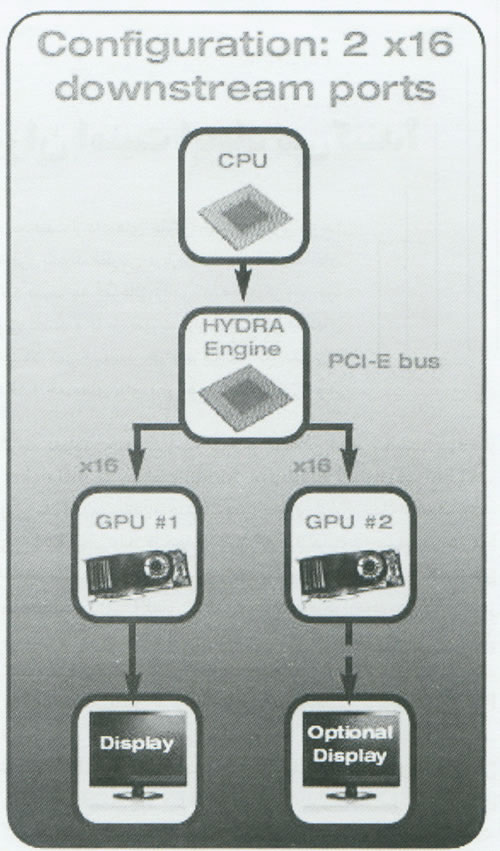
شماره مدل درگاه های Downstream درگاه های Upstream تعداد GPU های پشتیبانی شده LT22114 8×2 8×1 2 LT22102 16×2 16×1 2 LT24102 16×2 16×1 2، 3 و یا 4 درگاه های Upstream در جدول [1] به تعداد مسیرهای PCI-E در اتصال مابین Hydra 200 با کنترلر CPU/PCI-E اشاره دارند. درگاه های Downstream به تعداد مسیرهای PCI-E در اتصال مابین Hydra 200 و GPUها اشاره دارد. برای مثال، LT22102 دارای دو اتصال Downstream از نوع x16 PCI-E و یا بعبارت دیگر یک اتصال x16 با هریک از GPUها می باشد.
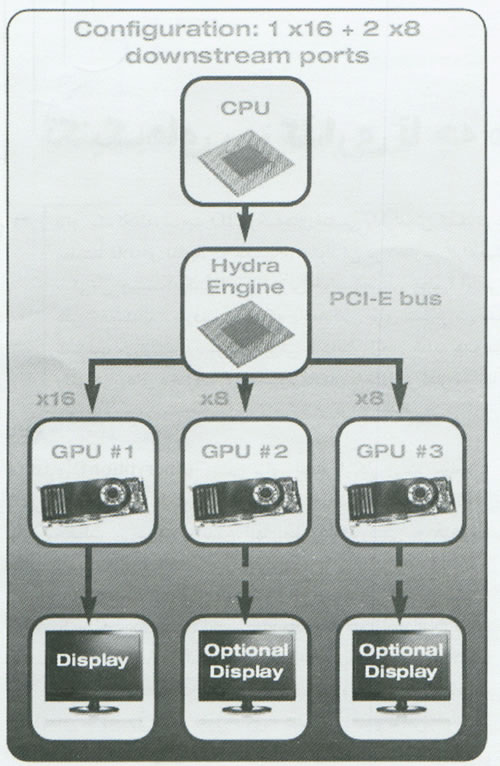
در مدل سطح بالای LT24102 که پیکربندی آن در شکلهای [3] تا [5] نشان داده شده است، اتصالات Downstream با GPUها بر حسب تعداد GPUهای داخل سیستم تغییر می کنند. برای مثال با دو GPU، پیکربندی بصورت دو اتصال x16 PCI-E خواهد بود( یک اتصال برای هر GPU). با سه GPU، شما یک اتصال X16 و دو اتصال x8 را در اختیار خواهید داشت. با چهار GPU، تراشه LT24102 این اتصالات GPU را بطور خودکار پیکربندی می نماید، یا این هدف نهائی که بهترین استفاده از منابع موجود را فراهم کند. در اینجا به هیچ تعامل از سوی کاربر نیاز نخواهد بود.
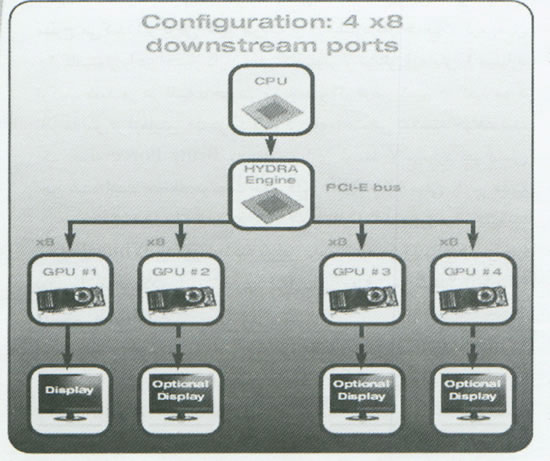
Hydra 200 بعنوان یک تراشه Add-on قابل خریداری نخواهد بود، بلکه باید در داخل یک مادربرد پیاده سازی گردد و این بدان معنی است که هرگونه هزینه مربوط به Hydra در هزینه کلی یک مادربرد محاسبه خواهد گردید. با وجود آنکه Lucid قیمت دقیق تراشه های Hydra 200 را بطور عمومی اعلام نکرده است، اما این شرکت مدعی است که هزینه اضافه شده برحسب مدل Hydra 200 مورد استفاده تقریباً معادل 1/5 دلار برای هر مسیر PCI-E خواهد بود. برای مثال، تراشه سطح بالای LT24102 شانزده مسیر Upstream و 32 مسیر Downstream را در اختیار دارد. براساس این ارقام، می توان تخمین زد که اضافه کردن یک تراشه Hydra 200 LT24102 به یک مادربرد تقریباً 72 دلار به هزینه آن خواهد افزود. منبع: بزرگراه رایانه، شماره 129
این صفحه را در گوگل محبوب کنید
[ارسال شده از: راسخون]
[مشاهده در: www.rasekhoon.net]
[تعداد بازديد از اين مطلب: 999]

-
گوناگون
پربازدیدترینها