

دکتر علی پرند فوق تخصص جراحی پلاستیک
طراحی سایت فروشگاهی فروشگاه آنلاین راهاندازی کسبوکار آنلاین طراحی فروشگاه اینترنتی وبسایت
بهترین دکتر پروتز سینه در تهران
بهترین ماساژورهای برقی برای دیسک کمر در بازار ایران
بهترین ماساژورهای برقی برای دیسک کمر در بازار ایران
آفریقای جنوبی چگونه کشوری است؟
بهترین فروشگاه اینترنتی خرید کتاب زبان آلمانی: پیک زبان
با این روش ساده، فروش خود را چند برابر کنید (تستشده و 100٪ عملی)
سفر به بالی؛ جزیرهای که هرگز فراموش نخواهید کرد!
از بلیط تا تماشا؛ همه چیز درباره جشنواره فجر 1403
دلایل ممنوعیت استفاده از ظروف گیاهی در برخی کشورها
آیا میشود فیستول را عمل نکرد و به خودی خود خوب میشود؟
مزایای آستر مدول الیاف سرامیکی یا زد بلوک
خصوصیات نگین و سنگ های قیمتی از نگاه اسلام
مطالب سایت سرگرمی سبک زندگی سینما و تلویزیون فرهنگ و هنر پزشکی و سلامت اجتماع و خانواده تصویری دین و اندیشه ورزش اقتصادی سیاسی حوادث علم و فناوری سایتهای دانلود گوناگون
تعداد کل بازدیدها :
1861019307












راهنمای کامل برای تنظیم دقیق T5 برای Text2Text و ساخت نسخه نمایشی با Streamlit
واضح آرشیو وب فارسی::
همه چیزهایی که برای ساختن یک دمو کامل باید بدانید: Hugging Face Hub، Tensorboard، Streamlit و Hugging Face Spaces
من شده است مایل به آزمایش با Streamlit و در آغوش گرفتن فضاهای چهره برای مدتی در حال حاضر. در صورتی که شما آنها را نمی دانستید:
- استریملیت یک کتابخانه پایتون است که به دانشمندان داده اجازه می دهد تا به راحتی دموهای تعاملی کوچکی ایجاد کنند، به طوری که افراد دیگر می توانند مدل های یادگیری ماشین خود را آزمایش کنند یا تحلیل های داده های خود را ببینند. اتمام گالری Streamlit برای یادگیری آنچه می تواند با کتابخانه انجام می شود. همچنین, شما می توانید برنامه Streamlit خود را به ابر Streamlit استقرار, که باعث می شود آن را آسان برای به اشتراک گذاشتن برنامه های کاربردی خود را با افراد دیگر و شما سی پی او رایگان برای اجرای برنامه های کاربردی خود را. من پیشنهاد می کنم داشتن یک نگاه به Gradio نیز هست، که یکی دیگر از کتابخانه های محبوب پایتون با اهداف مشابه است.
- در آغوش گرفتن فضاهای چهره یک سرویس است که در آن شما می توانید برنامه های کاربردی Streamlit یا Gradio خود را مستقر به طوری که شما به راحتی می توانید آنها را به اشتراک بگذارید. این فراهم می کند سی پی او رایگان و آن را شبیه به ابر Streamlit. با این حال ، هنگامی که شما استقرار یک برنامه در Hugging چهره فضاهای است که با استفاده از یک مدل یادگیری ماشین آپلود شده در Hugging چهره هاب ، هر می تواند ببینید که آنها مرتبط هستند (به عنوان یکی ، که نسخه ی نمایشی تعاملی برای آن مدل وجود دارد).
برای تست آنها، من تصمیم گرفتم به لحن خوب یک مدل از پیش آموزش دیده در یک کار ساده اما نه چندان محبوب، که نسل عناوین نامزد برای مقالات با شروع از محتوای متنی خود را.
این کاری است که قرار است در این مقاله انجام دهیم:
- یافتن مجموعه داده های مناسب حاوی مقالات مطالب متنی و عناوین.
- یک متریک مناسب برای وظیفه ما انتخاب کنید.
- ریز لحن یک مدل از پیش آموزش دیده برای تولید عنوان در کولاب، نظارت بر متریک انتخاب شده بر روی مجموعه اعتبار سنجی با استفاده از TensorBoard، و صرفه جویی در های بازرسی مدل در گوگل درایو (به طوری که ما می توانیم آموزش در مورد Colab خاموش اتصال از سر گرفته).
- آپلود مدل در Hugging چهره هاب برای همه به استفاده از.
- ساخت یک نسخه ی نمایشی تعاملی با Streamlit و استقرار آن را به در آغوش گرفتن فضاهای چهره.
بيا شروع کنيم!
انتخاب مجموعه داده ها برای وظیفه نسل عنوان
من معمولا به دنبال مجموعه داده ها در جستجوی مجموعه داده های گوگل و یا Kaggle. در حال حاضر مجموعه داده ها در دسترس با بسیاری از مقالات روزنامه وجود دارد، اما برای این آموزش من می خواستم به نوع مقالات است که ما معمولا در متوسط پیدا کنید تمرکز: اخبار کمتر، راهنمای بیشتر.
از آنجا که من می تواند یک مجموعه داده مقالات متوسط شامل هر دو مقالات محتویات متنی و عناوین پیدا کنید ، من یکی توسط خودم با خراش وب سایت و تجزیه صفحات وب با استفاده از کتابخانه پایتون روزنامه ایجاد شده است. من سپس آن را به Kaggle با نام آپلود 190k + متوسط مقالات مجموعه داده ها به طوری که هر می تواند آن را استفاده کنید ، همراه با یک نوت بوک عمومی با اکتشاف داده های ساده.
هر ردیف در داده ها مقاله متفاوتی است که در Medium منتشر می شود. برای هر مقاله، شما دارای ویژگی های زیر می باشد:
- title [string]: The title of the article.
- متن [رشته]: محتوای متن مقاله.
- url [رشته]: URL مرتبط با مقاله.
- authors [list of strings]: The article authors.
- timestamp [string]: The publication datetime of the article.
- tags [لیست رشته ها]: لیست برچسب های مرتبط با مقاله.
انتخاب یک متریک برای وظیفه نسل عنوان
وظیفه تولید عناوین با شروع از محتوای متنی یک مقاله یک وظیفه تولید متن2متن است: ما یک متن در ورودی داریم و می خواهیم برخی متن ها را به عنوان خروجی تولید کنیم.
وظایف محبوب نسل text2text ترجمه ماشین، معمولا با نمره BLEU و تمرکز بر دقت کلمه ارزیابی می شود، و خلاصه سازی متن، معمولا با نمره ROUGE و تمرکز بر فراخوان کلمه ارزیابی می شود.
من نسل عنوان را نزدیک به خلاصه متن می بینم چرا که عنوان باید خواننده را درک کند که مقاله در مورد چه چیزی است، با طعم اضافه شده که عنوان نیز باید خواننده را فتنه کند و او را در مورد مقاله کنجکاو کند. به همین دلیل تصمیم گرفتم مدل هایم را با نمره ROUGE ارزیابی کنم.
آموزش مدل
بیایید پرش در حال حاضر به کد با کولاب! شما می توانید تمام کد در این نوت بوک کولاب عمومی نیز پیدا کنید. این کاری است که ما انجام خواهیم داد:
- اتصال گوگل درایو به کولاب به ذخیره سازی مداوم در سراسر جلسات Colab.
- دانلود مجموعه داده های متوسط از Kaggle.
- مجموعه داده ها را بارگذاری کنید.
- مجموعه داده ها را به قطار، اعتبار سنجی و مجموعه آزمون تقسیم کنید.
- مجموعه داده ها را برای T5 از پیش پردازش می کند.
- آماده سازی مربی چهره در آغوش گرفتن.
- شروع TensorBoard.
- لحن خوب T5.
- مدل را امتحان کنید.
- ارزیابی مدل بر روی مجموعه آزمون.
ابتدا برخی کتابخانه ها را نصب می کنیم:

ما با استفاده از کتابخانه ترانسفورماتور چهره transformers در آغوش گرفتن برای دانلود مدل های از پیش آموزش دیده و لحن خوب آنها، کتابخانه datasets مجموعه داده چهره در آغوش گرفتن به بار مجموعه داده های ما و پیش پردازش آن، کتابخانه rouge-score برای محاسبه نمرات ROUGE، و کتابخانه nltk که شامل توابع مشترک NLP پیش پردازش.
اتصال درایو گوگل به کولاب
در اینجا یک نوت بوک Colab فراهم می کند که دستور العمل برای بارگذاری و صرفه جویی در داده ها در کولاب از منابع خارجی است. ما به بخش "نصب Google Drive به صورت محلی" علاقه مند هستیم: با اجرای کد زیر در نوت بوک ما، از شما خواسته می شود که به نوت بوک اجازه دهید داده ها را از Google Drive خود بخواند.

سپس می توانید داده های Google Drive خود را در دایرکتوری drive/MyDrive کنید. بعدها در این مقاله، ما های بازرسی مدل ما را در داخل یک درایو هدفمند ایجاد شده drive/MyDrive/Models کنید.
دانلود مجموعه داده های متوسط از Kaggle
ما مجموعه داده های ما با استفاده از kaggle دانلود, که می آید در حال حاضر بر روی کولاب گوگل نصب شده. برای استفاده از دستور kaggle آن را از طریق یک کلید API به حساب Kaggle خود متصل کنیم. در اینجا دستورالعمل برای ایجاد کلید API ، آن را بسیار آسان است. پس از انجام, شما باید kaggle.json
بعد، شما نیاز به آپلود فایل kaggle.json عنوان مثال Colab خود را. اگر نمی دانید چگونه این کار را انجام دهید، بخش "آپلود فایل ها از سیستم فایل محلی" این نوت بوک را بررسی کنید.
در نهایت، ما نیاز به دستور kaggle به استفاده از kaggle.json را. شما می توانید این کار را با اجرای kaggle فرمان ، که دایرکتوری پنهان .kaggle (همراه با پرتاب خطا به دلیل آن را نمی تواند یک فایل kaggle.json در داخل دایرکتوری .kaggle پیدا کنید). سپس، فایل را به دایرکتوری با cp kaggle.json ~/.kaggle/kaggle.json.
ما هم اکنون می توانیم مجموعه داده ها را دانلود کنید! اول، ما باید نام مجموعه داده ها را بازیابی کنیم، که هر چیزی است kaggle.com/datasets/ در URL مجموعه داده ها می آید. URL مجموعه داده های kaggle.com/datasets/fabiochiusano/medium-articles، بنابراین نام مجموعه داده ها فابیوچیوسانوfabiochiusano/medium-articles. اجرای دستور kaggle datasets download -d fabiochiusano/medium-articles / متوسط مقالات ، و شما باید فایل متوسط مقالات ، .zip در medium-articles.zipدایرکتوری فعلی خود را پیدا کنید.
بار مجموعه داده ها
بیایید کتابخانه های لازم را وارد کنیم.

مجموعه داده ها را با استفاده از load_dataset بسته datasets کنیم.
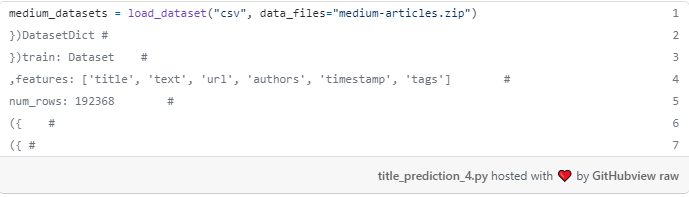
تقسیم مجموعه داده ها به قطار، اعتبار سنجی، و مجموعه آزمون
به عنوان یک عمل رایج، مجموعه داده ها را به:
- مجموعه آموزش: داده های مورد استفاده برای آموزش پارامترهای مدل.
- مجموعه اعتبارسنجی: داده های مورد استفاده برای تنظیم هایپرپارامتر یا توقف زودهنگام برای جلوگیری از اضافه کاری.
- مجموعه آزمون: داده های مورد استفاده برای بررسی اینکه چه عملکردی را می توانیم بر روی داده های جدید انتظار داشته باشیم.
این کار را می توان با train_test_split از شی مجموعه داده های ما، به عنوان زیر انجام داد.
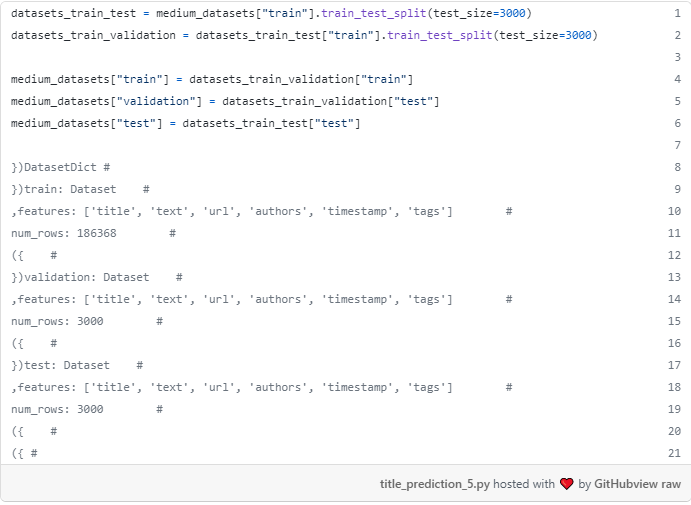
انتخاب اندازه های سه مجموعه داده معمولاً به عوامل زیادی بستگی دارد، مانند اندازه کل مجموعه داده ها، اینکه چقدر زمان می خواهید آموزش یا ارزیابی مدل خود را صرف کنید و ارزیابی های مدل تان چقدر دقیق باشد. از آنجا که ما در حال آموزش یک مدل کاملا بزرگ در GPU رایگان از Colab، من تصمیم گرفتم به استفاده از اعتبار سنجی کوچک و مجموعه آزمون برای سرعت بخشیدن به همه چیز. با وجود این شاهد خواهیم بود که مدل نهایی قادر خواهد بود عناوین خوبی تولید کند.
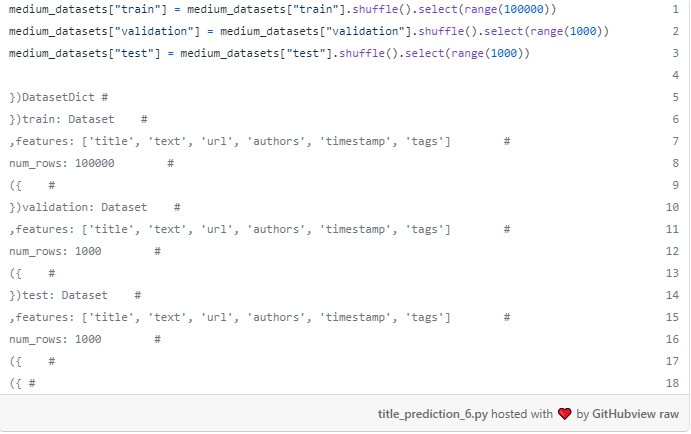
پیش پردازش مجموعه داده ها برای T5
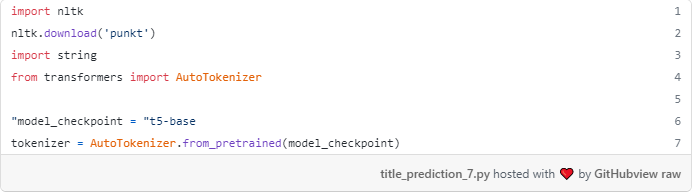
در آغوش گرفتن چهره ما را با یک مثال کامل نوت بوک از چگونگی ریز لحن T5 برای خلاصه متن فراهم می کند. همانطور که برای هر مدل ترانسفورماتور، ما نیاز به ابتدا به نشانه گذاری داده های آموزش متنی: محتوای مقاله و عنوان.
بیایید لحظه ای نشانه گذار از مدل T5 پایه.
قبل از اعمال نشانه ساز بر روی داده ها، بیایید برخی از نمونه های بد را فیلتر کنیم (به عنوان نمونه مقالاتی که عنوان آن ها طولانی تر از ۲۰ کاراکتر است و محتوای متنی آن ها طولانی تر از ۵۰۰ کاراکتر است).

سپس تابعی را تعریف preprocess_data که دسته ای از نمونه ها را به عنوان ورودی می گیرد و یک دیکشنری از ویژگی های جدید را برای اضافه کردن به نمونه ها خروجی می کند. تابع preprocess_data زیر را انجام می دهد:
- ویژگی «متن» را از هر نمونه استخراج کنید (به عبارتی محتوای متن مقاله)، خطوط جدید را در مقاله برطرف کنید و خطوط را بدون پایان دادن به نقطه گذاری (به معنی زیرنویس) حذف کنید.
- پیش فرض متن "خلاصه: " به هر متن مقاله، که برای تنظیم ریز T5 در وظیفه خلاصه مورد نیاز است.
- استفاده از نشانه ساز T5 به متن مقاله، ایجاد model_inputs شی. این شیء یک فرهنگ لغت شامل، برای هر مقاله، یک input_ids و attention_mask شامل input_ids شناسه های توکن و ماسکattention_mask های توجه به ترتیب است.
- استفاده از نشانه ساز T5 به عنوان مقاله، ایجاد labels. همچنین در این حالت، این شیء یک فرهنگ لغت شامل، برای هر مقاله، یک input_ids و یک آرایهattention_mask حاوی شناسه های توکن و ماسک های توجه به ترتیب است. توجه داشته باشید که این مرحله در داخل tokenizer.as_target_tokenizer() انجام می شود: این کار معمولاً به این دلیل انجام می شود که وظایف text2text وجود دارد که در آن ورودی ها و برچسب ها باید با نشانه سازهای مختلف نشانه گذاری شوند (مانند هنگام ترجمه بین دو زبان، جایی که هر زبان نشانه ساز خاص خود را دارد). تا آنجا که من می دانم، برای خلاصه سازی متن برچسب ها با نشانه گذار مشابه ورودی ها نشانه گذاری می شوند، در نتیجه مدیر زمینه اختیاری است.
- یک فرهنگ لغت حاوی شناسه های توکن و ماسک های توجه ورودی ها، و شناسه های توکن برچسب ها را برگردانید.
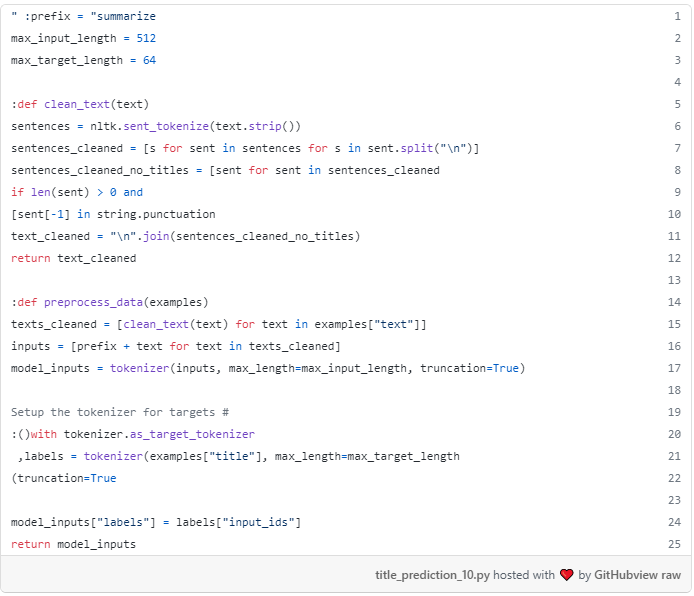
داشته باشید که ما در حال truncating ورودی در 512 نشانه. در حالی که T5 می تواند ورودی های طولانی تر را مدیریت کند، نیازهای حافظه به طور درجه دو با اندازه ورودی ها رشد می کنند، و این حداکثر اندازه ای بود که من می توانستم در توجه جلسه کولاب خود استفاده کنم. ۵۱۲ توکن با حدود ۶۸۲ کلمه انگلیسی مطابقت دارد که کم و بیش چیزی است که یک فرد به طور متوسط در دو دقیقه می خواند. اکثریت مقالات متوسط بین چهار تا هفت دقیقه زمان خواندن دارند، بنابراین ما در حال حاضر اطلاعات مفیدی را برای وظیفه خود دور می اندازیم. با وجود این، بسیاری از مقالات آنچه را که در پاراگراف های اول خود در مورد آن هستند، می گویند، بنابراین عناوین خوبی را می توان در اکثر مناسبت ها تولید کرد.
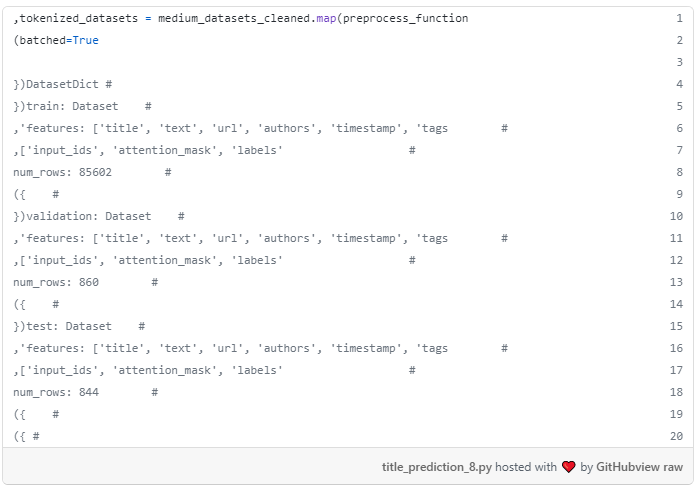
تابع preprocess_data می تواند به تمام مجموعه داده ها با روش نقشه map شود.
آماده سازی مربی چهره در آغوش گرفتن
ما در حال حاضر می تواند خوب لحن T5 با داده های از پیش پردازش شده ما! بیایید برخی از کلاس های لازم برای آموزش مدل های text2text وارد کنید.

بعد، ما نیاز به ایجاد یک شی Seq2SeqTrainingArguments شامل، به عنوان نام نشان می دهد، پارامترهای آموزشی متعددی است که تعریف خواهد کرد که چگونه مدل آموزش دیده است. مراجعه به اسناد Trainer برای دانستن در مورد معنی هر یک از این پارامترها.
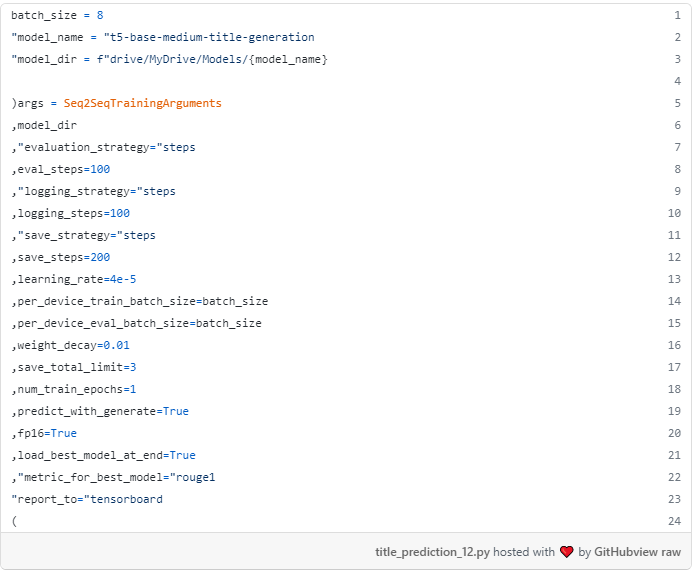
در اینجا توضیح برخی از پارامترهای غیر معمول منتقل شده به Seq2SeqTrainingArguments شی:
- predict_with_generate: باید برای محاسبه متریک های مولد مانند True ROUGE و BLEU به True تنظیم شود.
- fp16: آیا به جای آموزش 32 بیتی از آموزش دقیق fp16 16 بیتی (مختلط) استفاده کنید. آموزش را سریع تر می کند.
- report_to: فهرست ادغام ها برای نوشتن سیاهههای مربوط به.
توجه داشته باشید که دایرکتوری خروجی در داخل گوگل درایو است و ما در حال مشخص rouge1 به عنوان متریک است که تعریف بهترین مدل.
بعد، ما یک شی DataCollatorForSeq2Seq را با استفاده از نشانه ساز لحظه ای می کنیم. کلاتورهای داده اشیایی هستند که با استفاده از فهرستی از عناصر مجموعه داده ها به عنوان ورودی و در برخی موارد، اعمال برخی پردازش ها، دسته ای را تشکیل می دهند. در این حالت، تمام ورودی ها و برچسب ها در یک دسته به حداکثر طول مربوطه خود را در دسته خالی خواهد شد. بالشتک ورودی ها با توکن معمول [PAD] انجام می شود، در حالی که بالشتک برچسب ها با یک توکن با شناسه -۱۰۰انجام می شود که نشانه ویژه ای است که به طور خودکار توسط توابع از دست دادن PyTorch نادیده گرفته می شود.

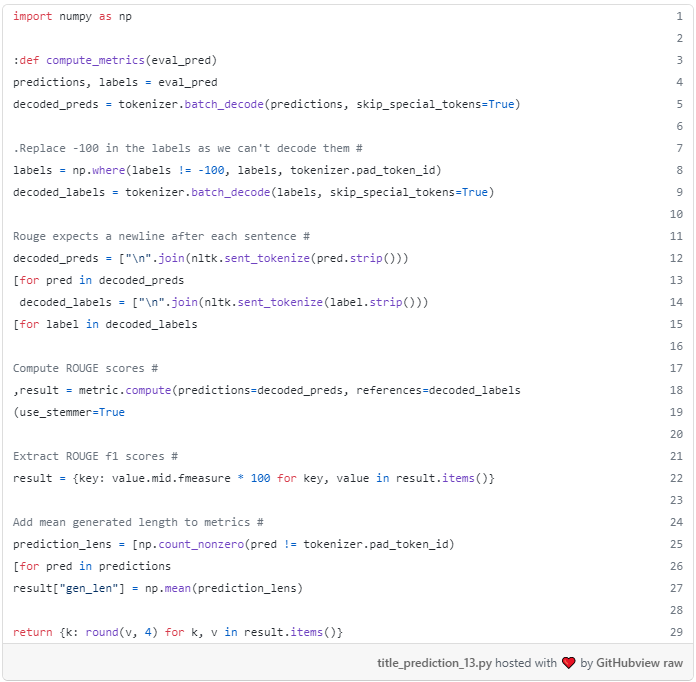
بعد، کد ROUGE را با استفاده از تابع load_metric کتابخانه datasets داده ها دانلود می کنیم و به این ترتیب یک شیء متریک را لحظه ای می کنیم. سپس می توان از این شیء برای محاسبه متریک های خود با استفاده از پیش بینی ها و برچسب های مرجع استفاده کرد.

جسم متریک پس از آن باید در داخل یک تابع compute_metrics نامیده می شود که طول می کشد tuple از پیش بینی ها و برچسب مرجع به عنوان ورودی، و خروجی یک فرهنگ لغت از متریک محاسبات بیش از ورودی.metric به طور خاص، compute_metrics تابع زیر را انجام می دهد:
- پیش بینی ها را رمزگشایی کنید (به عبارتی از شناسه توکن گرفته تا کلمات).
- برچسب ها را پس از جایگزینی شناسه توکن -100 با شناسه توکن [PAD] رمزگشایی کنید.
- محاسبه نمرات ROUGE با استفاده از پیش بینی ها و برچسب های رمزگشایی شده، و تنها زیرمجموعه ای از این متریک ها را انتخاب کنید.
- محاسبه یک متریک جدید، که طول متوسط پیش بینی ها است.
- یک دیکشنری را برگرداند که کلیدهای آن نام های متریک ها هستند و مقادیر آن مقادیر متریک هستند.
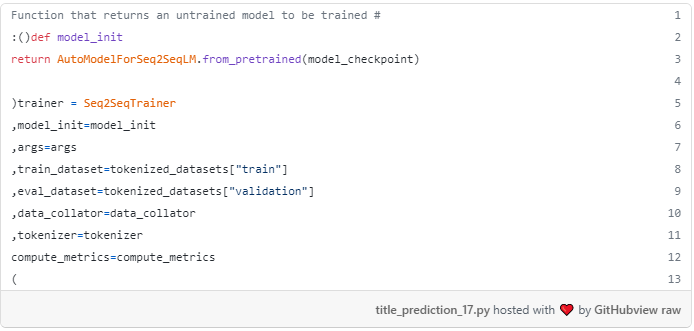
ما تقريبا ً تموم شديم! ما اکنون باید یک Seq2SeqTrainer ایجاد کنیم که تمام اشیاء را که به تازگی تعریف کرده اند عبور می دهد: استدلال های آموزشی، داده های آموزش و ارزیابی، کلاتور داده ها، نشانه ساز، تابع compute_metrics، و یک تابع model_init. تابع model_init باید یک نمونه جدید تازه از مدل از پیش آموزش دیده را به لحن خوب بازگشت، مطمئن شوید که آموزش همیشه از همان مدل شروع می شود و نه از یک مدل تا حدی ریز کوک شده از نوت بوک خود را.
شروع TensorBoard
قبل از شروع آموزش، بیایید TensorBoard را در داخل دفترچه مان شروع کنیم.

پس از اجرای این کد، نوت بوک باید TensorBoard را درست زیر سلول نمایش دهد.
ریز لحن T5
آخرین، ما تنظیم ریز را با روش قطار شروع train کنیم.

پس از شروع، سلول یک نوار پیشرفت نشان دهنده تعداد دسته های پردازش شده خروجی. همچنین، در هر چرخه ارزیابی، مقادیر متریک های ما بر روی مجموعه اعتبارسنجی را نیز خواهیم دید، که در تصویر بعدی می توانید آن را ببینید.
تعداد هر مرحله نشان دهنده تعداد دسته های پردازش شده است. به عنوان مثال در مرحله ۱۰۰ مدل بر روی ۱۰۰ 100 * batch_sizeآموزش دیده است که در این حالت ۱۰۰ 100 * 8 = 800.
هر دو تلفات آموزش و ارزیابی به تدریج تا مرحله 2100 کاهش می یابد. با این حال، به نظر می رسد تمام متریک های ROUGE در حدود مرحله ۱۵۰۰ به اوج خود رسیده اند و بعدها کمی کاهش یافته اند. از آنجا که آموزش در حال حاضر در زمان حدود سه ساعت، من تصمیم گرفتم برای جلوگیری از آموزش و تست نتایج، اما غیر ممکن نیست که نمرات ROUGE می تواند دوباره پس از برخی از مراحل افزایش یافته است، در نتیجه باعث می شود من از دست یک مدل بهتر است.
طول متوسط عناوین تولید شده همواره در حدود ۱۲ نشانه پایدار باقی مانده است. همانطور که هر نشانه با نشانه های زیر کلمه کم و بیش طولانی 0.75 کلمات انگلیسی است، ما می توانیم یک برآورد سریع است که طول متوسط مقالات تولید شده در حدود 9 کلمه است (به نظر می رسد خوب!).
در اینجا برخی از نمودارهای استخراج شده از TensorBoard.
از دست دادن آموزش به نظر می رسد در حدود گام 1700 تثبیت, به آرامی کاهش.
از دست دادن ارزیابی هنوز هم در مرحله 2000 در حال کاهش است. طول متوسط عناوین تولید شده تا حدودی در ۱۲ نشانه در طول آموزش پایدار باقی می ماند.
روژ-۱ در مرحله ۱۸۰۰ در ۳۳٪ تثبیت می شود، در حالی که ROUGE-2 در ۱۷٫۵٪ در مرحله ۱۵۰۰ تثبیت می شود.
ROUGE-L و ROUGE-L-sum هر دو در 30.7٪ در مرحله 1500 تثبیت. در حالی که ROUGE-L طولانی ترین زیرمجموعه مشترک (LCS) بین متن تولید شده و متن مرجع نادیده گرفتن newlines را محاسبه می کند، ROUGE-L-sum با در نظر گرفتن خطوط جدید به عنوان مرزهای جمله همان کار را انجام می دهد.
مدل را امتحان کنید
ما هم اکنون می توانیم مدل خود را آزمایش کنیم! اول، بيا بارش کنيم.
بیایید آن را در صفحه وب "اضافه کردن statefulness به برنامه ها" از اسناد Streamlit را امتحان کنید.

مدل ما عنوان "وضعیت جلسه و Callbacks در Streamlit" را پیش بینی می کند. به نظر خوب مياد!
ما آن را در مقاله متوسط "بانکداری در رباتها" به عنوان یک مثال دوم تست.

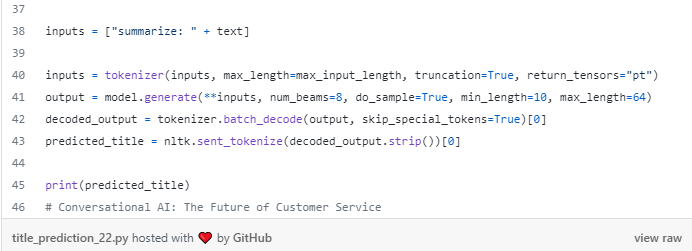
مدل پیش بینی عنوان "هوش مصنوعی مکالمه ای: آینده خدمات به مشتریان"، که منسجم با محتوای مقاله و دارای سرمایه گذاری مناسب نیز هست. به نظر می رسد مدل همان طور که انتظار می رفت کار می کند.
ارزیابی مدل بر روی مجموعه آزمون
آخرین، بیایید متریک های موجود در مجموعه آزمون را با مدل جدید محاسبه کنیم تا بررسی کنیم که آموزش به درستی انجام شده است و می توانیم انتظار عملکرد خوبی بر روی داده های جدید دیده نشده داشته باشیم.
ما باید:
- متن مقالات را به همان طول پد کنید.
- گروه نمونه ها را به دسته (با استفاده از dataloader PyTorch).
- تولید عنوان برای هر نمونه.
- عناوین تولید شده را با عناوین مرجع با استفاده از تابع compute_metrics شده قبلی مقایسه کنید.
متریک ها بهتر از متریک هایی هستند که از مجموعه اعتبارسنجی هستند. احتمالا باید اندازه هر دو مجموعه اعتبارسنجی و آزمون را افزایش دهیم تا نتایج متغیر کمتری داشته باشد، اما بیایید این نتایج را در حال حاضر رضایت بخش در نظر ب گیریم.
آپلود مدل در آغوش گرفتن چهره هاب
بارگذاری مدل از گوگل درایو خسته کننده است از آنجایی که ما نیاز به سوار آن را به سیستم فایل های Colab هر بار. بیایید ببینیم چگونه مدل خود را در Hugging Face Hub آپلود کنیم.
هنگامی که آپلود مدل خود را به هاب چهره در آغوش گرفتن، آن را تمرین خوبی برای آپلود آن را با هر یک از سه چارچوب اصلی یادگیری عمیق مدیریت شده توسط Hugging چهره: PyTorch، تانسورفلو، و JAX. بنابراین، ما نیاز به نصب JAX برای تبدیل مدل ما، آن را به عنوان آن را در کولاب به طور پیش فرض نصب نشده است.
سپس، ما نیاز به تصدیق به حساب چهره در آغوش گرفتن ما، به عنوان مدل های آپلود خواهد شد به آن مرتبط است.
آخرین، ما مدل خود را در سه فرمت آپلود می کنیم. به یاد داشته باشید برای آپلود نشانه ساز نیز هست!
پس از تکمیل، این است که چگونه ما می توانیم مدل و نشانه ساز را از هاب بارگذاری کنیم. توجه داشته باشید که نام مدل پیش از نام حساب مرتبط با آن است.
به یاد داشته باشید برای به روز رسانی کارت مدل مدل آپلود شده خود را. این مرحله شامل به روز رسانی README در داخل مخزن مدل شما است. نگاهی به کارت مدل نهایی مدل ما داشته باشد!
ساخت یک نسخه ی نمایشی تعاملی با Streamlit و استقرار آن را به در آغوش گرفتن فضاهای چهره
بیایید دوباره خط کد است که ما استفاده می کنیم برای تولید عنوان نامزد برای یک مقاله را ببینید.
همانطور که می بینید ، ما با استفاده از پارامترهای متعددی از generate به لحن نتایج. یک پارامتر رایج مورد استفاده در هنگام تولید متن temperatureدما است، که کنترل tradeoff بین به دست آوردن قطعی ترین نتایج احتمالی و به دست آوردن نتایج قابل قبول متفاوت (اما تا حدودی کمتر احتمالی) هر بار که ما اجرای تابع. در واقع ممکن است بخواهیم به جای یک عنوان نامزد 10 عنوان نامزد تولید کنیم.
همچنین مدل ما تنها 512 نشانه اول متن مقاله را در هنگام تولید عناوین نامزدها در نظر می گیرد. اگر بخواهیم عناوین متعددی تولید کنیم، جایی که هر عنوان با در نظر گرفتن ۵۱۲ نشانه از بخش های متمایز مقاله تولید می شود، چه؟ ما نیاز به اضافه کردن منطق پیش بینی سفارشی به مدل، که به راحتی قابل آزمایش به طور مستقیم از هاب چهره در آغوش گرفتن نیست.
با این حال، راهی برای اجازه دادن به کاربران برای آزمایش با این تنظیمات وجود دارد: ما می توانیم یک نسخه ی نمایشی کوچک با این منطق سفارشی با استفاده از Streamlit بسازیم!
من نمی خواهم به جزئیات کد با Streamlit, اما مطمئن باشید که آن را بسیار آسان برای استفاده و سریع برای یادگیری. من پیشنهاد می کنم خواندن اسناد Streamlit، آن را چند ساعت طول می کشد.
نگاهی به این repo برای دیدن کد کامل از برنامه Streamlit ما. دو جزء اصلی وجود دارد:
- پرونده app.py: حاوی کد Streamlit برنامه است. این جایی است که ما مدل خود را از هاب چهره در آغوش گرفتن بارگذاری می کنیم، برخی اجزای تعاملی ایجاد می کنیم، و مقداری منطق برای اتصال این دو می نویسیم.
- پرونده requirements.py: شامل تمام کتابخانه های پایتون مورد استفاده در فایل app.py (مانند کتابخانه transformers است. لازم نیست کتابخانه Streamlit را به این پرونده اضافه کنید.
هنگامی که ما به صورت محلی برنامه Streamlit ما تست و همه چیز کار می کند به عنوان انتظار می رود, ما نیاز به آپلود آن را به فضای چهره در آغوش گرفتن جدید. این مرحله فقط یک موضوع از کپی کردن فایل های برنامه های کاربردی Streamlit خود را به repo جدید ایجاد شده در حساب چهره در آغوش گرفتن خود را. مراجعه به این مقاله برای یادگیری نحوه میزبانی پروژه های Streamlit خود را در آغوش گرفتن فضاهای چهره.
این در نتیجه Hugging چهره فضا است که با استفاده از مدل تولید عنوان ما در پس زمینه و اجازه می دهد تا تولید عناوین متعدد (با در نظر گرفتن دهانه های مختلف متن مقاله) و تغییر temperature.
بیایید سعی کنید تولید 5 عنوان نامزد برای "بانکداری در رباتها" مقاله متوسط ، با استفاده از درجه حرارت temperature 0.6.
عناوین تولید شده عبارتند از:
- هوش مصنوعی مکالمه : دستیار تاکتیک واقعی برای خدمات به مشتریان
- آینده هوش مصنوعی مکالمه
- هوش مصنوعی مکالمه ای: یک رویکرد تحول دیجیتال
- موج بعدی هوش مصنوعی مکالمه ای
- هوش مصنوعی مکالمه: آینده خدمات به مشتریان
ساخت یک نسخه ی نمایشی کوچک با Streamlit بسیار آسان است و در رابطه با در آغوش گرفتن فضاهای چهره و یا Streamlit ابر، اجازه می دهد تا افراد دیگر برای تست کار خود را بدون نیاز به دانش چگونه برای اجرای نوت بوک Jupyter.
نتیجه گیری و مراحل بعدی
در این مقاله، ما یک مجموعه داده و متریک مناسب برای وظیفه نسل عنوان خود را انتخاب کردیم، و ما برخی از کدها را با کتابخانه Hugging Face نوشتیم تا یک مدل T5 از پیش آموزش دیده را برای وظیفه مان تنظیم کنیم. ما سپس مدل جدید ما را به هاب چهره در آغوش آپلود به طوری که همه می توانند از آن استفاده کنید، و ما ساخته شده یک برنامه نسخه ی نمایشی با Streamlit است که در حال حاضر به عنوان یک فضای چهره در آغوش میزبانی.
من معتقدم در آغوش گرفتن فضای چهره یک راه بی زحمت برای ساخت نمونه کارها از برنامه های کاربردی NLP که در آن مردم و یا سازمان ها می توانند نشان دادن مهارت های یادگیری ماشین خود را است.
مراحل بعدی ممکن است:
- ریز لحن یک مدل رمزگشایی کننده Longformer (LED) به جای T5، به عنوان آن قادر به استفاده از یک زمینه طولانی تر به عنوان ورودی است. به خاطر داشته باشید که آموزش کندتر خواهد بود هر چند.
- ریز لحن مدل BART و مقایسه نتایج در برابر مدل T5 ریز کوک شده است.
با تشکر از شما برای خواندن! اگر شما علاقه مند به یادگیری بیشتر در مورد NLP، به یاد داشته باشید به دنبال NLPlanet در متوسط، LinkedIn، توییتر، و پیوستن به سرور دیسکورد جدید ما !
این صفحه را در گوگل محبوب کنید

-